
Welcome back in this series of blogs regarding Cloud Native Storage. Check my previous on Cloud Native Storage: Overview for the introduction.
In this one, I will discuss about the process involved in choosing a cloud native storage product. If you remember my previous blog, I pasted the exhaustive (big!) list of products. Of course, if you are familiar with Kubernetes you’ll probably know that we can create multiple storage classes, and you are right. The point here is more about choosing a product that will fit a specific workload.
Workload can be of several kinds.
- Databases
- Stateless/stateful application
- Monitoring stack
- Web applications
- Big datatest
- Microservices architectures
- e-commerce
- Healthcare sensitive data
- Machine learning
First approach – Know your constraints
It’s mandatory to know what are the constraints when thinking about your workload. Let’s try to list some of them and determine which ones are relevant to your use case
- Reliability and durability
- Scalability
- Performance
- Security
- Cloud/On premise
- Storage type (S3, nvme, …)
- Cost
- Lifecycle management
- Observability
- Ease of use
- Vendor support
- Popularity
There is so much to say regarding each constraints, that’s why I mentioned to do a short list of main constraints and secondly to weight them. This will help you focus on essential expectations. Let’s take an example with cost. You may remember that products with a white background are open source, it not only means the product is free to use but also that you’ll be able to compare different products and why not also compare a proprietary product with trials that are often offered.
We can also take the performance constraint. This one is essential with relational databases workload. If it’s your case and you’re new with the topic, you’ve probably chosen the local PV storage to maximize latency and throughput, but with more experience you’ll find that products like
- Portworx that allows you to control IOPS or throughput at the storage layer here.
- Linbit that has impressive IOPS performance here
Adoption
Another constraint example I would like to talk about is popularity. Most of the products should be either supported by vendor or adopted by majority of the community so it guarantees you (a certain degree) of confidence to use it. My opinion reflect of course a “majority adopter” posture. In case your posture is “early”, it means you probably contribute to open source, then I just want to say “Thank you!” and keep going. I hope I will also be able to contribute in a near future. In case your posture is “laggards”, then continue your analysis with PoC to gain confidence.
You’ll find below the Innovation model lifecycle from Wikipedia.
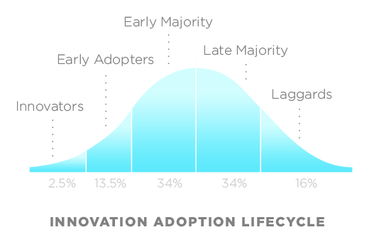
All kinds of adopters have their pros and cons and contribute to the community by giving feedbacks from their usage.
This brings me to the next point I wanted to mention in this blog. How can we discuss with contributors, users and vendor.
Let’s take the easy point with vendor. If you have something to discuss (issue, remarks, usage, feedback) the official vendor communication channels (e-mail, slack, sales, ticket, etc …) will be the best.
Now, regarding open-source products, there are severals way to discuss points, you have official vendor communication channels (e-mail, slack, sales, ticket, etc …) and also what you can find from people usage (stackoverflow, reddit, …).
Of course, said like that open-source has more possibility to get you answer. But the main difference is SLA with a product you paid for, vendor will have to give you an answer in a defined timeframe regarding the priority given to your ticket.
Conclusion
All discussed points brings us to the final words that
- There is no silver bullet solution
- You have to know and weight your constraints
- You need to know where you stand regarding adoption
We, at dbi services, can provide support to help you choose and also accompany you on your journey to understand the CNCF. Don’t hesitate to post comments or contact our sales team for support.
In the next blog, I’ll go deeper with a concrete example of a database workload that will leverage on a cloud native storage.
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GRE_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ADE_WEB-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/NME_web-min-scaled.jpg)