
Last week, I attended the AWS Summit Switzerland 2024 in Zürich with one of my colleague from the Cloud team. These kind of events are interesting to see the trends and stay informed on what’s new in AWS Cloud. There are no surprises for this year, the generative AI is still a very hot topic.

This short blog is about some key topics I found interesting to keep an eye on.
Amazon Bedrock
Training its own Large Language Model (LLM) requires a lot of data and compute resources. And there are already several public LLMs available. The goal of Amazon Bedrock is to provide access to some foundational models (like Anthropic, Meta, etc…) as a fully managed service.
It can be used for content generation and help you to build your own virtual assistant. Clariant showed an example with their new company assistant named Clarita mentioned in the keynote by Chris Hansen and with a dedicated presentation later on.
Being between your users and the model you want to query helps you to implement Guardrails to prevent leak of sensitive data or filter the result to match your internal policies. Generative AI is a big trend but security is big concern for many companies as data is a important asset of each company.
RAG helps improving results from foundational models
There are different approaches to customize foundation models and improve the results to match your context.
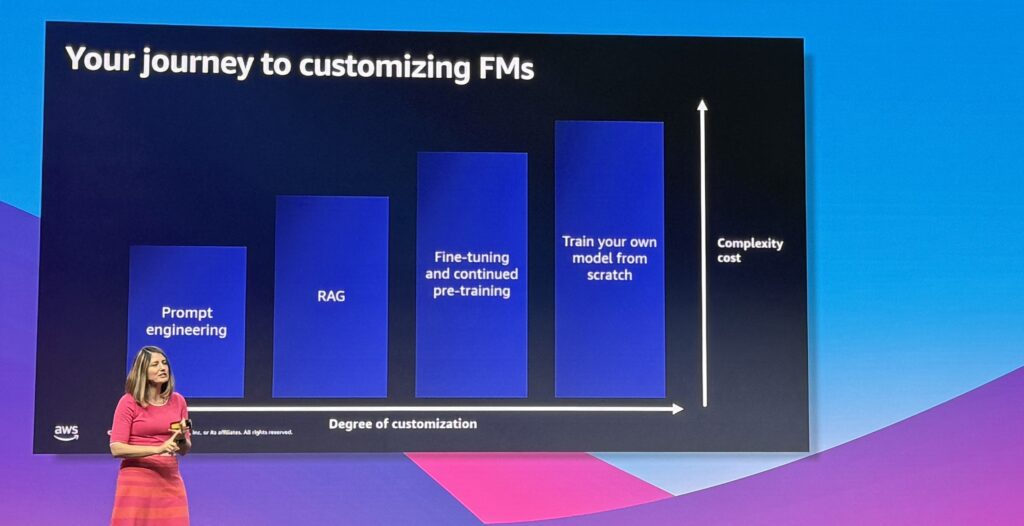
Prompt engineering does not really allow to use your own data and on the other side, training your own model brings a lot of complexity and require some investment. It leaves 2 options: Retrieval Augmented Generation (RAG) and Fine-tuning / pre-training on existing model.
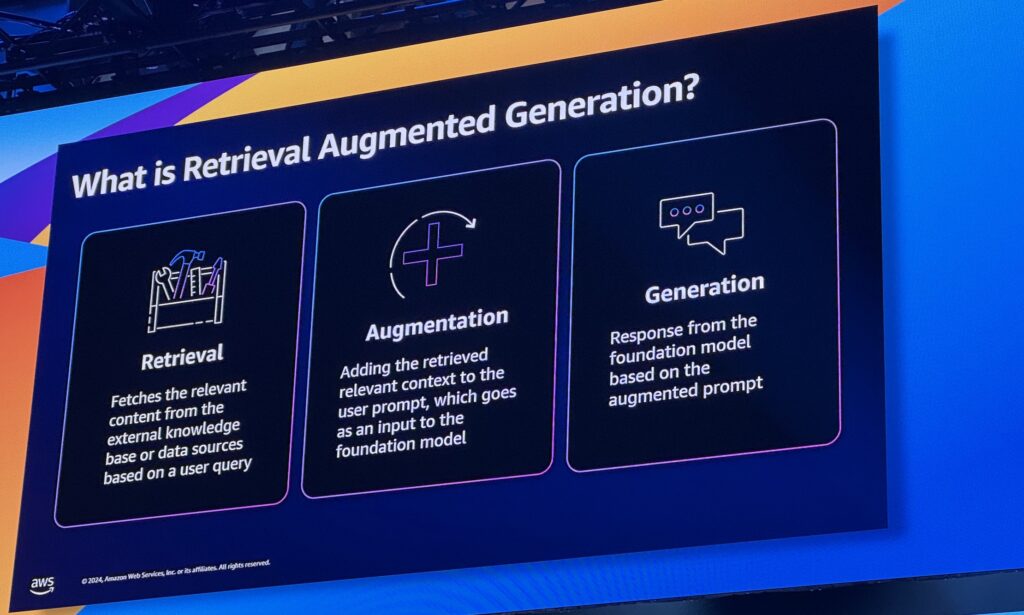
RAG was a really huge topic, it’s a good way to use your company data without the need to fine-tune and train your own model. In a simplified view, when the user submit its prompt, an additional search is done in a database or with an API and the result of that search is added to the prompt to provide context and data. The assistant Clarita I already mentioned above is built with RAG to help Clariant provide its employees answers with company data including old research data that has been digitalized.
Vector database will play a role
This topic is heavily related to generative AI and RAG. As shown in the picture below, the idea is to go through an embedding model and represents human language as vectors. It works in more than 3 dimensions, and the “distance” between 2 points helps to see if they are part of the same “space”
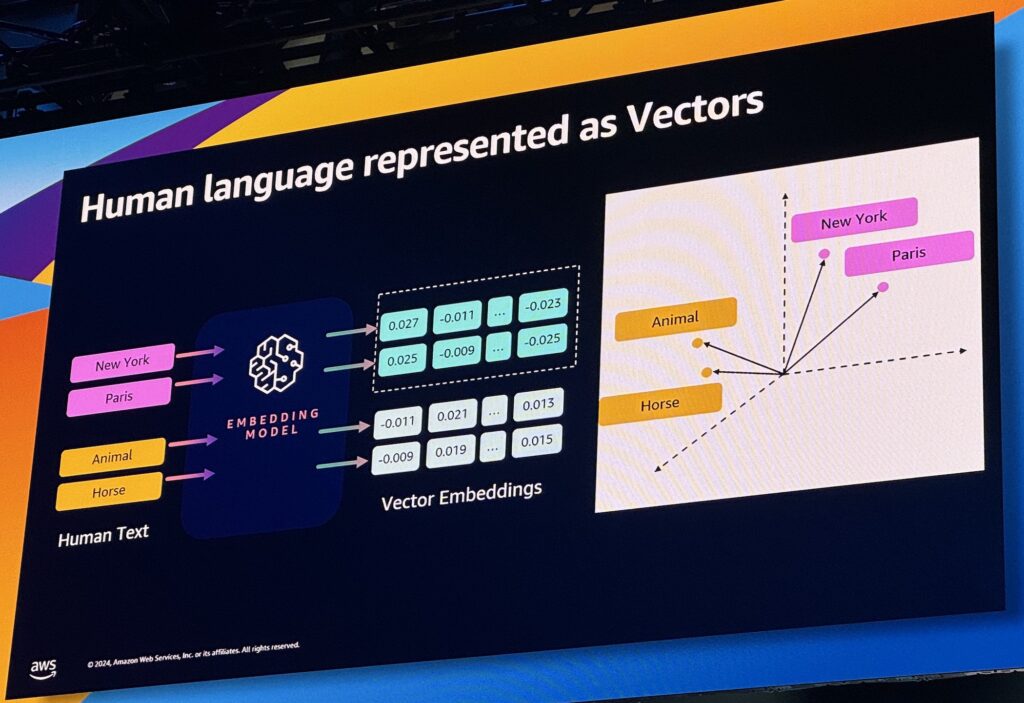
New York and Paris are 2 cities and the 2 vectors are closer with each other than with Horse or Animal which belong to a different space. There were different speeches around RAG and vector database and it seems to be the critical peace for a custom virtual assistant. Even when I went to a deep dive session on Aurora to keep my database knowledge, one of the feature named “pgvector extension” brings me back to AI trend.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/11/NIJ-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/05/JDE_Web-1-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ADE_WEB-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/07/ALK_MIN.jpeg)