
Of course today’s highlight was Werner Vogels’ keynote with is amazing presentation skills and some great announcements. You will for sure you will find plenty of articles about it.
On my side I will rather focus on 2 thematics which are a bit closer and relevant for daily operational activities: Network “debugging” and the Resilience Hub.
Network monitoring and tracing
For sure you already faced a situation where 2 instances should be communicating (for sure)…but do not :-(. That’s the point you are struggling with ping and traceroute trying to figure out if it is a route table issue or may be a security group configuration…
Here AWS has significantly extended the set of tools available to analyse what’s going on with your network:
- CloudWatch logs (100+ network related metrics)
- Route53 query logs (for DNS requests tracing)
- Network Manager
Network manager of central networking hub
Network Manager has really evolved to become your central network cockpit.
It provides you for instance a topology view to keep a visual overview of your network
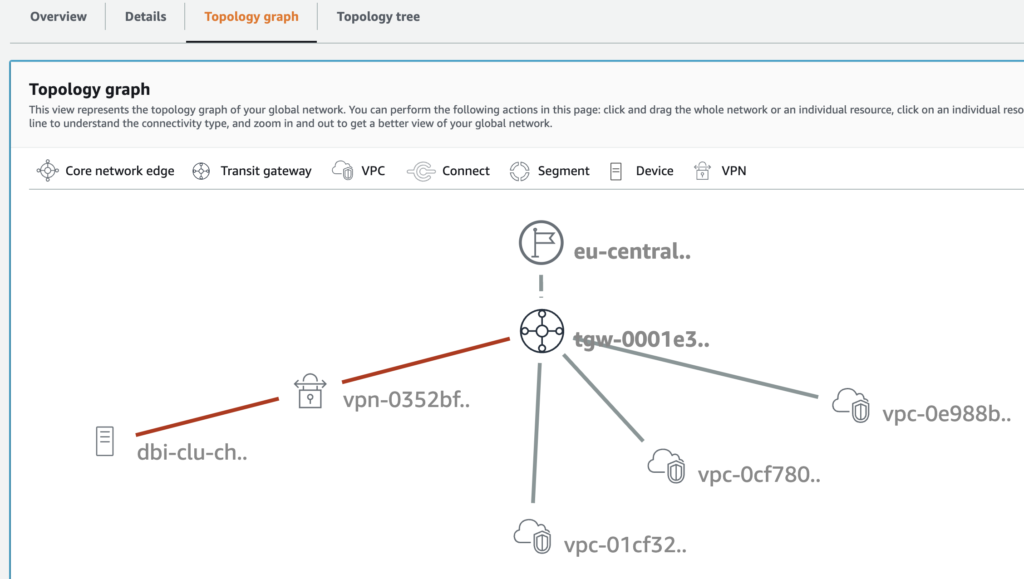
Then the interesting part are the analyzers:
- Reachability Analyzer
- Transit Gateway Route Analyzer
- Network Access Analyzer
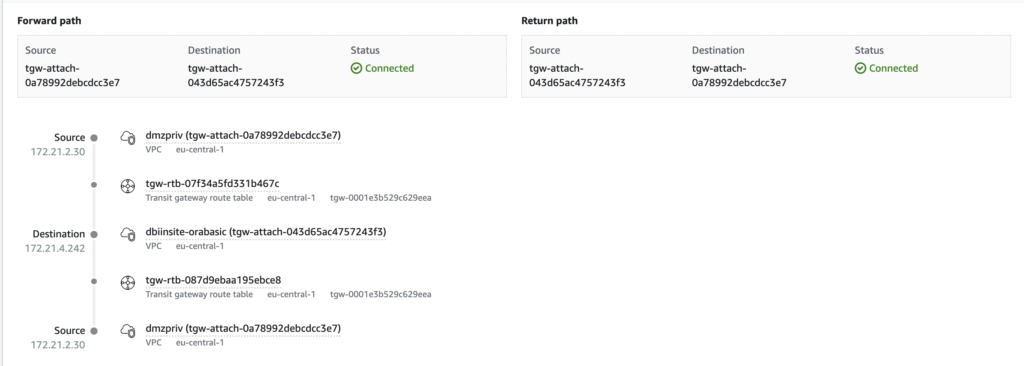
The 2 first will allow you to checkout the connectivity between 2 points within VPCs or through Transit Gateways and even cross account. It will show you the attachment, routing tables, security groups and even potentially the ACLs you are going through.
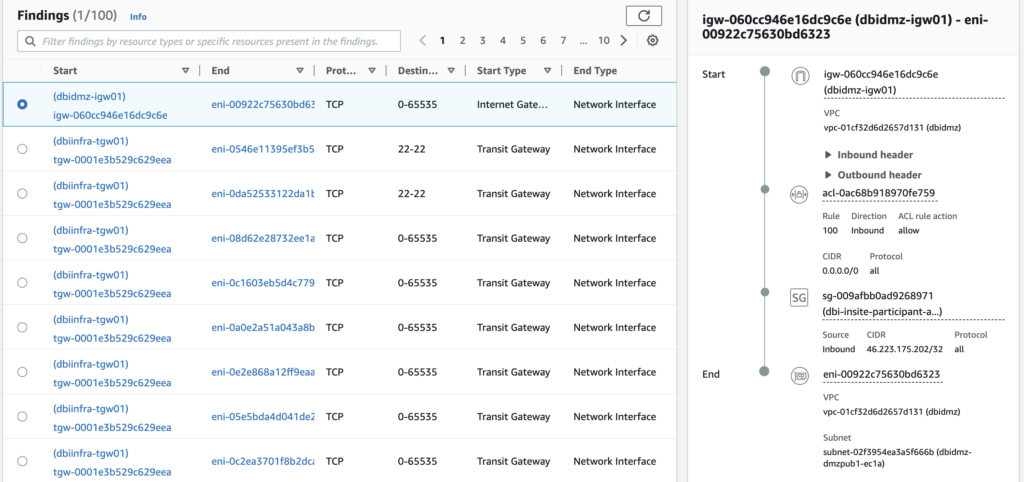
The Network Access Analyzer allows to defines scopes (4 templates are provided by default) to check where your resources have access and/or from where they are accessible. A pretty convenient tool to check your network segregation.
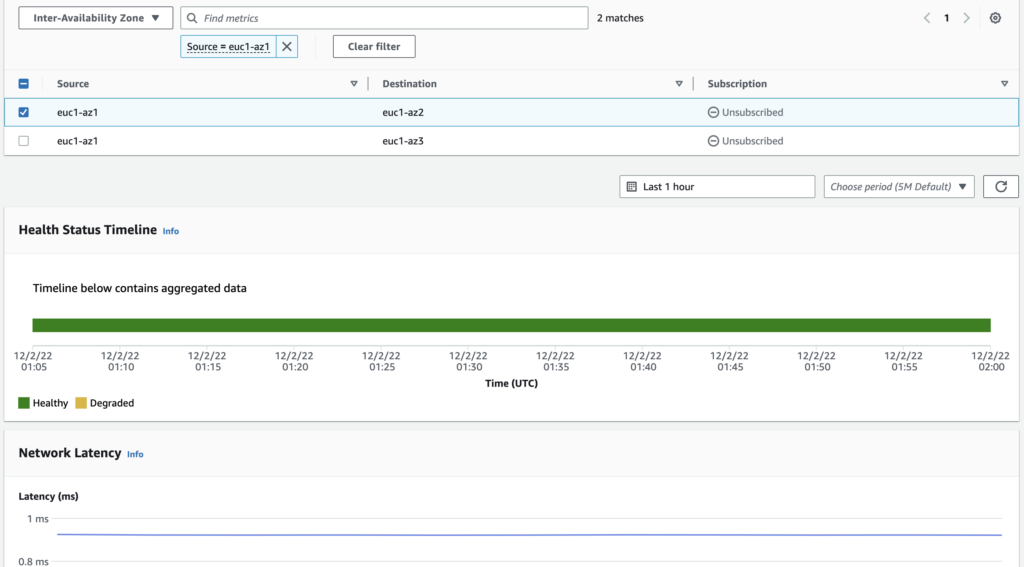
Last but not least, you can also check the health of the AWS global network with inter-region and inter-AZ status from the Infrastructure Performance menu
…and even your facing Internet status using the Internet Monitor report available as preview in CloudWatch 😎.
AWS Resilience hub
When setting an infrastructure for hosting one or more application, one of the key elements which shall never be under estimated is the infrastructure / application resilience.
The can be summarized by 2 simple questions
- How much can the application can be done?
–> RTO - How much data can be lost?
–> RPO
Even if regularly the first answer is 0 and 0 ;-), it requires deeper analysis and a some reflexion to find the right balance between resilience and costs.
To do so AWS provides you a great solution called the Resilience hub.
The principle is pretty simple:
On one hand you create a resilience policy defining the expected RTO and RPO either manually or using suggested policies.

On the other you will describe your application stack, which may look like something below
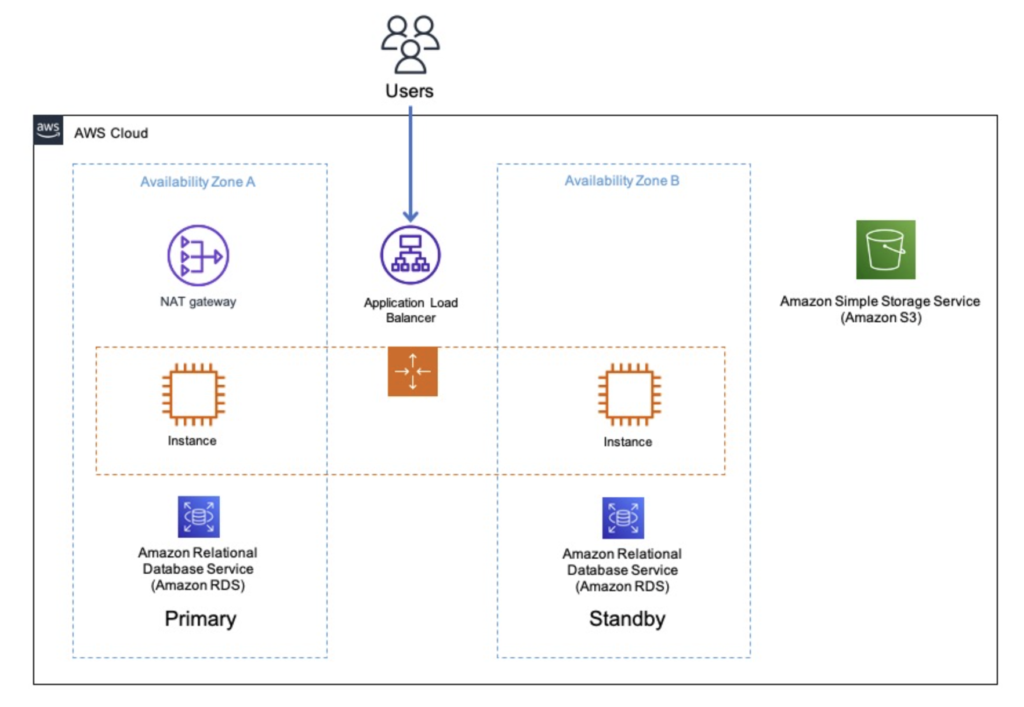
This is done by loading the stack in different supported formats:
- CloudFormation stacks
- Terraform state files
- Resource Groups
- App Registry
Then you simply link the application to the appropriated resiliency policy allowing you to:
- Assess your application
- Can be run manually, scheduled or even integrated in your CI/CD pipelines
- Get resilience recommendations
- taking several possibilities in account (minimal changes, cost optimized, AZ optimized, …)
- Get operational recommendations
- Monitoring (using CloudWatch alerts)
- SOP (standard operation procedures integrated as documents in Systems Manager)
- Chaos Engineering through fault injections
- Run experiments
Here an example of an assessment output based on the example application architecture given above:
- Assessment result

- Check the details to find out which layer is not compliant with the policy
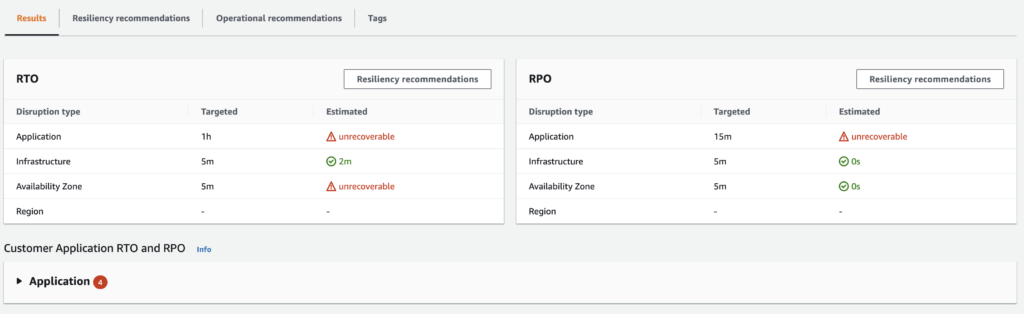
- View the on the layer (i.e. Application) which component need some improvements
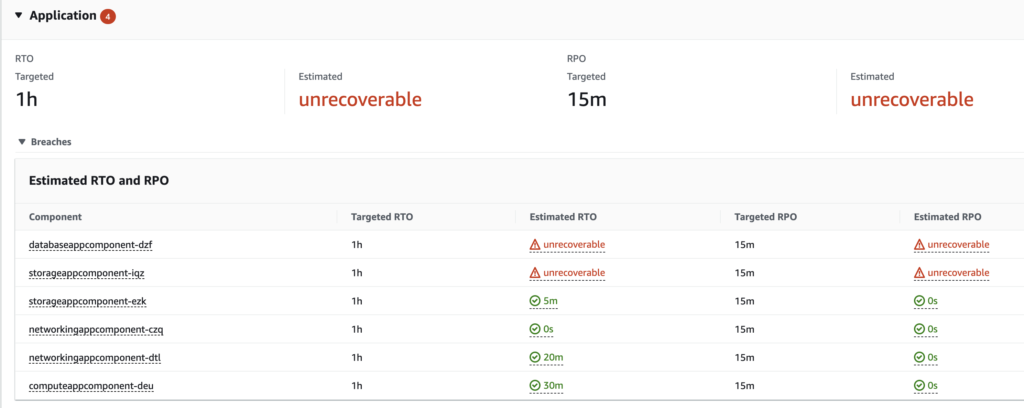
- View the recommendations to improve the resilience and the corresponding costs
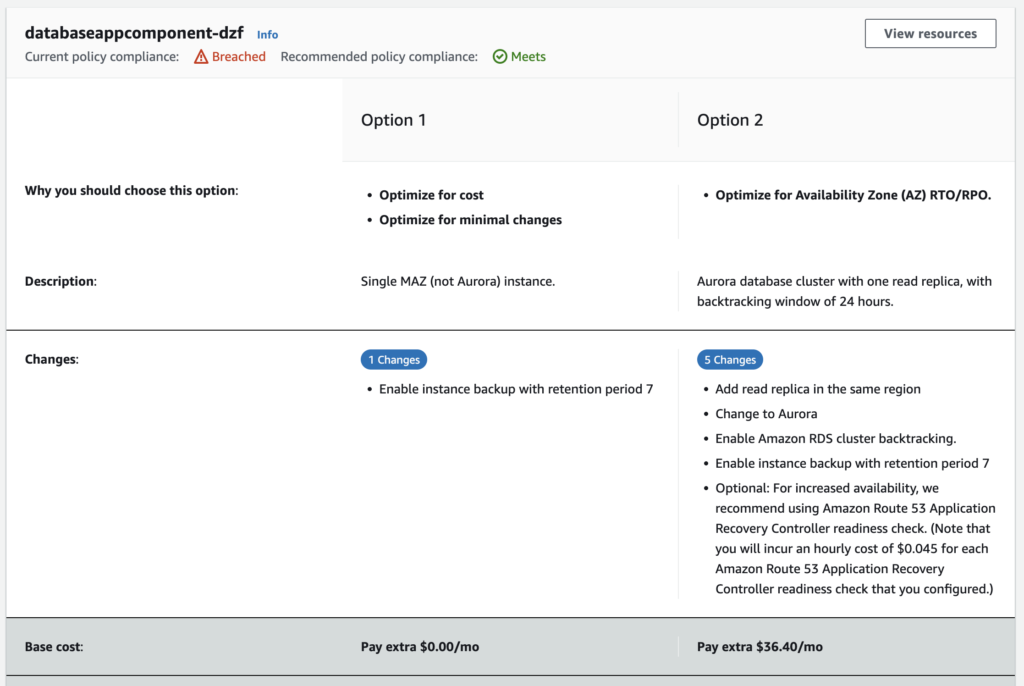
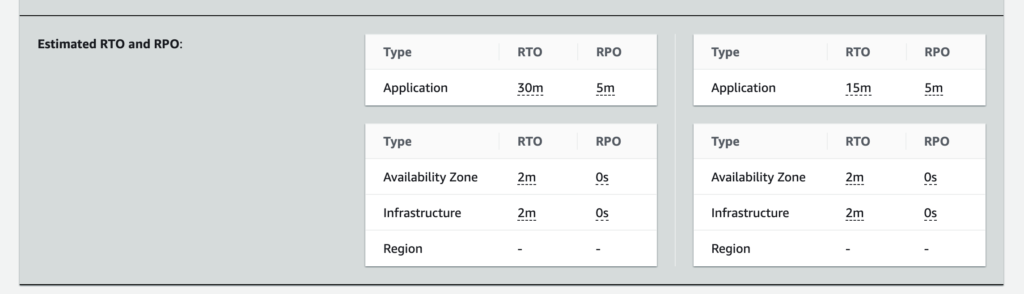
You even get an estimate of the impact of these changes on the RTO and RPO of your application
Definitively something I would recommend to test and use, especially that the price isn’t very high.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/DHU_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/07/ALK_MIN.jpeg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/05/JDE_Web-1-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ADE_WEB-min-scaled.jpg)