
So again during the 3rd day of the re:Invent 2022 there were plenty of interesting information to take with us. However, the most interesting part was for sure the workshop about gray failures and how to mitigate them in a multi-AZ environment. Let me try to wrap this up for you…
What are gray failures?
No idea what “gray failures stands” for? Let us try to reminder this situation, we for sure all already experienced, when users say “application ain’t working! Can’t work..” while at the same time on infrastructure side you hear “Nope everything green, no alerts there…..must be the network ;-)”
That’s grey failures. It means a non-binary situation where everything is working and not working at the same time. This kind of distorsion between application / users perception and system one.
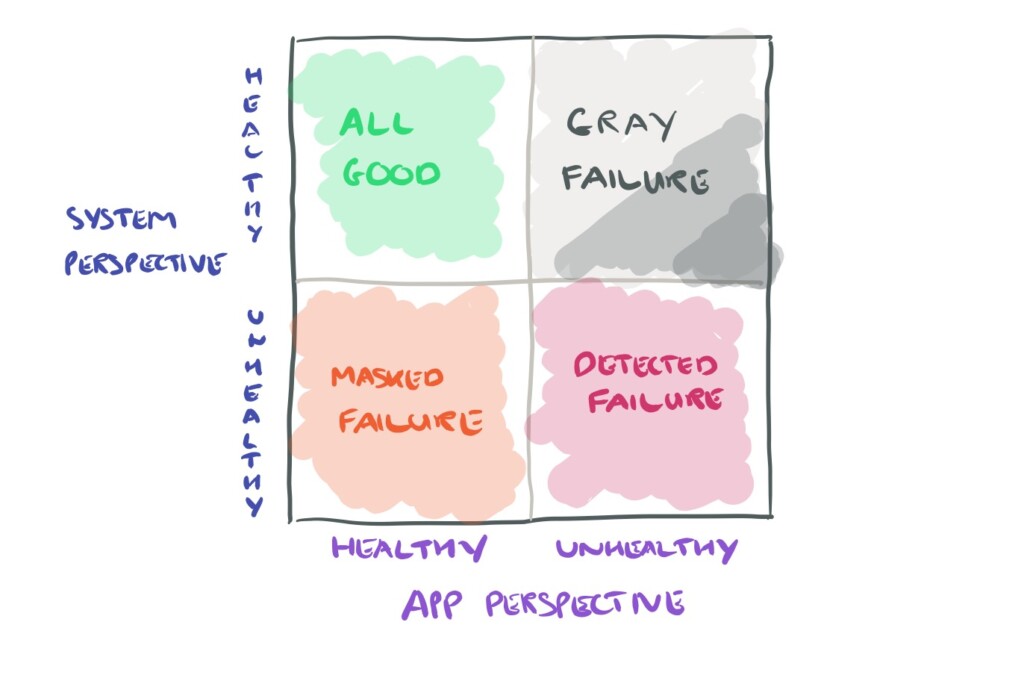
It is typically a conjonction of “small” issues that may even not breached any monitoring alerts thresholds, but that taken together makes the application unusable. Some researches even state that the biggest cloud outages are coming from these gray failures as part the so called failure circle.
Using a multi-AZ architecture on AWS, you can indeed try to detect and mitigate these gray failures.
Lets take a example a web based application running on 3 availability zone with load balancer and front-end web servers (as part of an auto scaling group) and a database as backend.
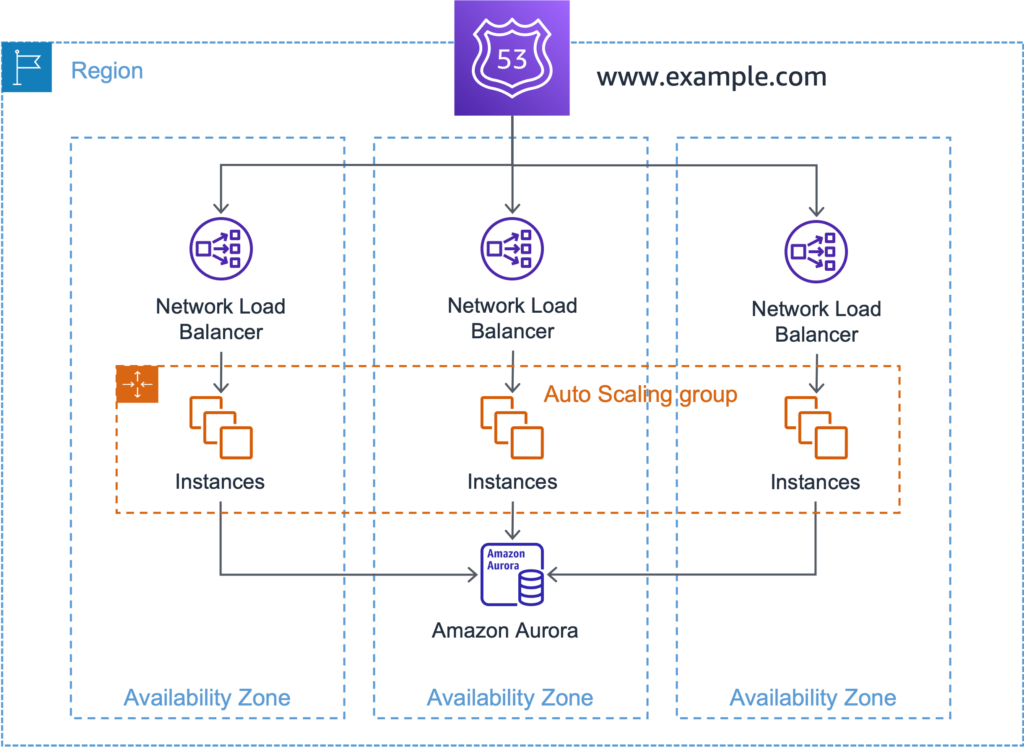
How to detect gray failures?
In case of gray failures our traditional monitoring approach (i.e. CPU > 96%, latency > 60ms, …) isn’t enough. Again the CPU may only be 95%…but the latency may also have reached 59ms…and at the same time we face some unusual amount of retransmitted packets due to a “tired” switch.
Do ou remember about “Murphy Law”? Everything which could go wrong…goes wrong…

On AWS CloudWatch can help you there
Using AWS CloudWatch you will at first create your traditional alerts (CPU, latency, …) but also region availability and latency. Then a second step, CloudWatch will allow you to create so called “composite alarms” which are exactly based on this principle of combining several alarms / metrics using simple AND OR NOT expressions

You can find much more information about detecting such gray failures in the AWS Advanced Multi-AZ Resilience Patterns whitepaper.
How to react?
Now that we have an idea on how we can detect these gray failure, the obvious questions is “how to react when it happens”.
The principle is pretty “easy”: Evict the AZ which is facing issues from our Multi-AZ architecture
This is the same principle than a cluster evicting a failed node.
To do so we can act on 2 levels:
1. Stop sending request to the LB of the affecting Load Balancer by deactivating this “route” in our Route53 DNS configuration
2. Stopping the instances in the faulty AZ and making sure the auto scaling group will bootstrap new ones in the remaining AZ
Disabling the DNS in Route53
Here the global idea. When the alert is raised you going to set a simple value in a DynamoDB table staing that the corresponding AZ in unhealthy.
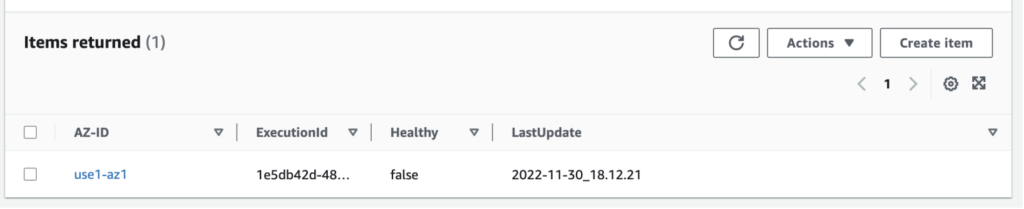
On Route53 you will have linked each DNS entry to an Health Check

What does this health check, which has been configured priori in Route53?
It will call the Amazon API Gateway to do a REST request to the DynamoDB table to check the healthy state of the corresponding AZ is.
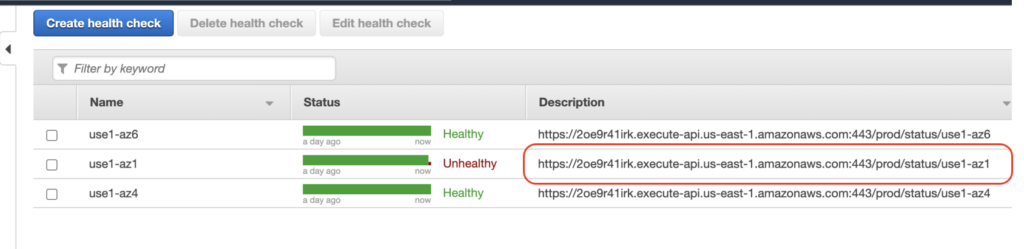
If the REST API comes back stating that the AZ is not healthy anymore (by sending a 4xx code back) then Route53 won’t send this path back until it get healthy again.
You can also have a look on the AWS article Creating Disaster Recovery Mechanisms Using Amazon Route 53.
Updating the auto scaling group
So now that our users aren’t sent to the faulty AZ anymore, the next step is to update the auto scaling group for my web front-end instances. This should automatically shutdown the one in the faulty AZ and start new ones in the remaining AZ.
To do so the idea is again to use a table in DynamoDB in which we will store the subnets of the faulty AZ.
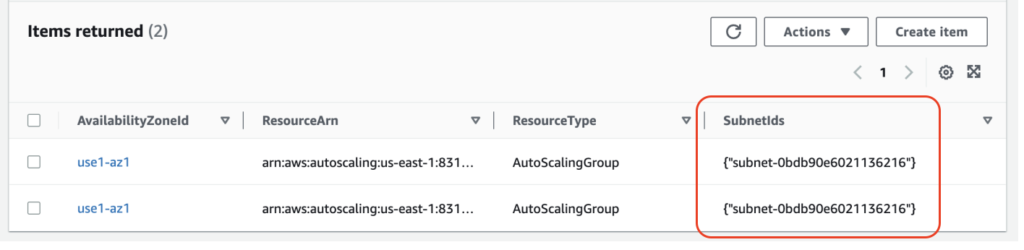
Finally we will simply run a Lambda function to update the auto scaling group to remove those subnets. As a consequence the instances running in them will be shutted down and new ones will be starting in the remaining AZ.

![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/DHU_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/07/ALK_MIN.jpeg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/05/JDE_Web-1-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ADE_WEB-min-scaled.jpg)