If you followed that last posts about DB Parameter Groups, Subnet Groups and Setting up the RDS instance you should have a running RDS instance. You should also be aware that changing parameters can not be done like you usually do it but you need to do that by changing the DB parameter groups. In this post we’ll look at how you can do that and, especially, what you should avoid.
Looking at our current configuration of the PostgreSQL RDS instance we can see that our DB Parameter Group is “in-sync”:
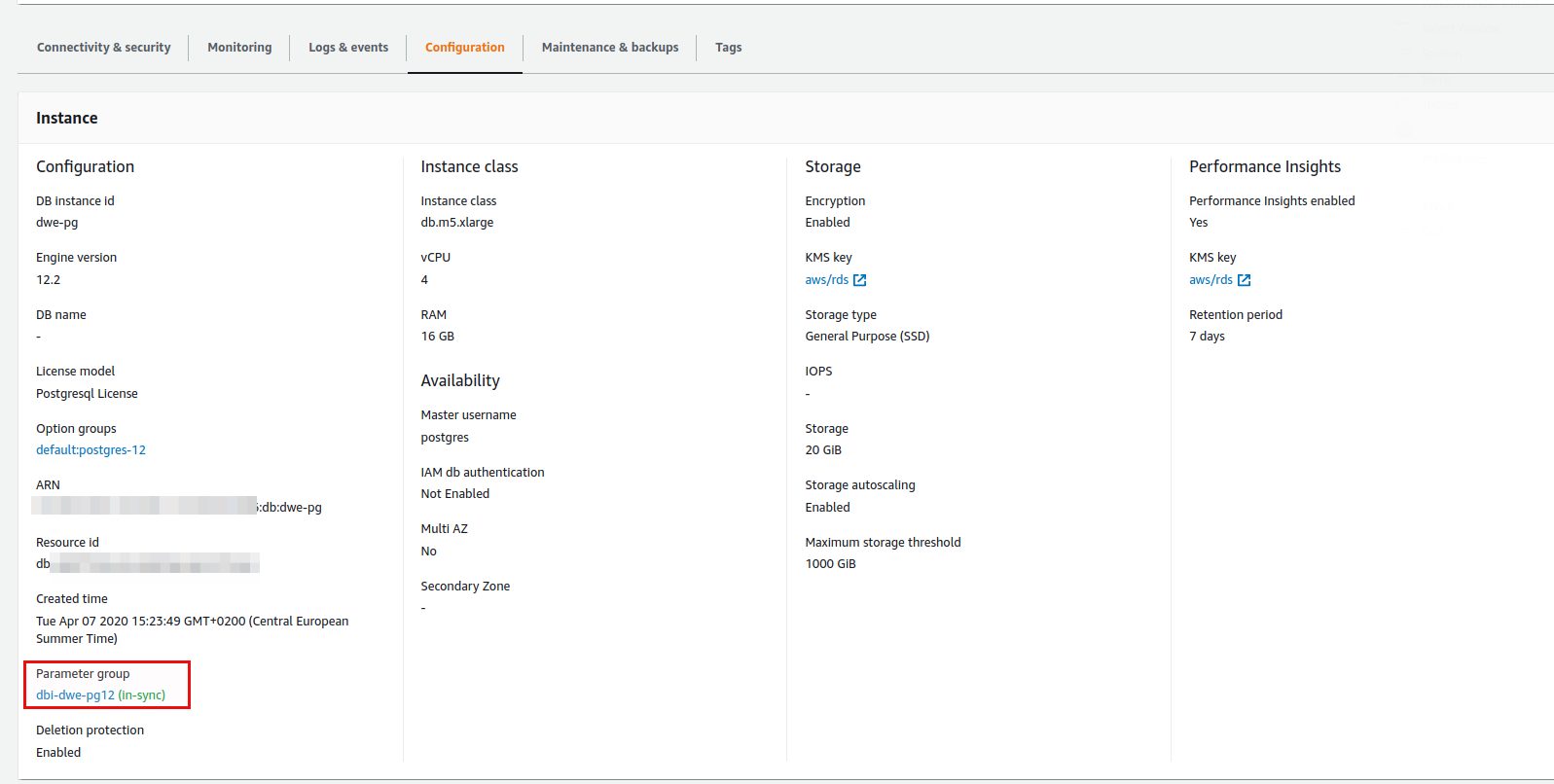
That means nothing changed or needs to be applied as all parameters of the instance have the same values as specified in the DB Parameter Group. Let’s go and change one of the parameters using the AWS console:

The parameter we’ll change is “autovacuum_naptime“, and we’ll change it from 15 to 20:

Once the changes are saved you’ll notice that the status in the configuration section changes to “applying”:
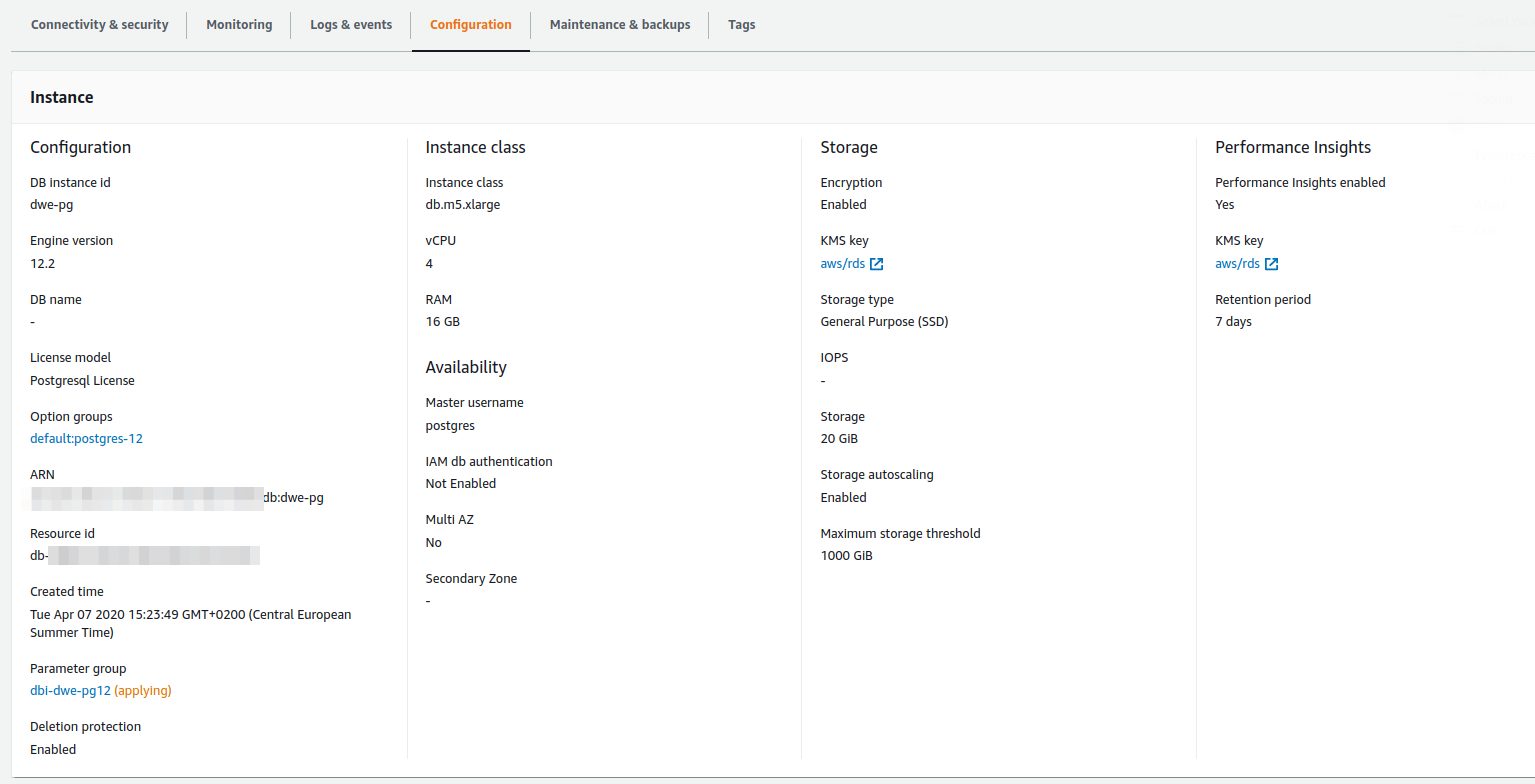
A few moments later the DB Parameter Group is “in-sync” again and the parameter is applied to the RDS instance:
postgres=> show autovacuum_naptime ; autovacuum_naptime -------------------- 20s (1 row)
Using the AWS command line utilities for these tasks usually is much easier and tasks can be automated. Changing the same parameter on the command line:
$ aws rds modify-db-parameter-group --db-parameter-group-name dbi-dwe-pg12 --parameters="ParameterName=autovacuum_naptime, ParameterValue=10, ApplyMethod=immediate"
You can already spot an important bit in the command: ApplyMethod=immediate. For dynamic parameters you have the choice to apply a new value immediately or “pending-reboot”. What happens if we change a static parameter using the AWS console?

Now we get a status of “pending-reboot”:
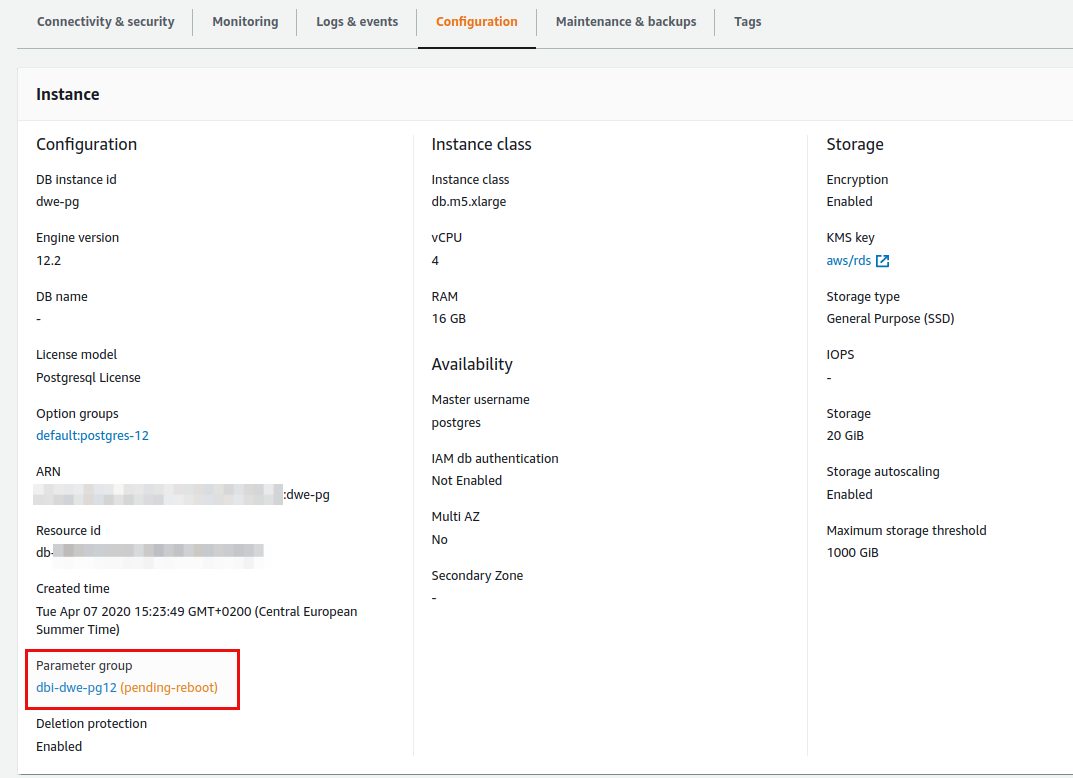
Rebooting the instance applies the parameter and the DB Parameter Group is in sync again:
postgres=> show autovacuum_naptime ; FATAL: terminating connection due to administrator command SSL connection has been closed unexpectedly The connection to the server was lost. Attempting reset: Succeeded. SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off) postgres=> show autovacuum_naptime ; autovacuum_naptime -------------------- 10s (1 row) postgres=> show max_locks_per_transaction ; max_locks_per_transaction --------------------------- 128 (1 row)
What you always need to be careful about it the instance type. Currently the instance is running db.m5.xlarge, which means we should have 16GB of memory available. Checking the current setting of shared_buffers we see that PostgreSQL uses 3GB from that 16GB for caching:
postgres=> show shared_buffers;
shared_buffers
----------------
3936960kB
(1 row)
postgres=> select 3936960/1024/1024;
?column?
----------
3
(1 row)
What happens when we set that to 32GB?

Will the instance come up after rebooting and what value will we see for shared_buffers?

We’ve managed to create a configuration set that will prevent the RDS from starting up. On the one hand this is expected, on the other hand I would have expected that there are some sanity checks in the background that prevent you from doing that. Maybe the reason AWS is not checking that is, that DB Parameter Groups can be used by several instances which all can run on different instance types. So, be careful, when you have a DB Parameter Group you are using for more than one instance and you want to change settings like shared_buffers. Keep in mind that you need check the instance type, because that defines your amount of memory and CPUs.
By using the command line utilities we can also check the PostgreSQL log file, which confirms why the instance is not able to start up:
dwe@dwe:~/Documents/aws$ aws rds describe-db-log-files --db-instance-identifier dwe-pg DESCRIBEDBLOGFILES 1586431187000 error/postgres.log 13626 DESCRIBEDBLOGFILES 1586267878000 error/postgresql.log.2020-04-07-13 8632 DESCRIBEDBLOGFILES 1586269968000 error/postgresql.log.2020-04-07-14 6211 DESCRIBEDBLOGFILES 1586426381000 error/postgresql.log.2020-04-09-09 8236 DESCRIBEDBLOGFILES 1586429793000 error/postgresql.log.2020-04-09-10 6096 DESCRIBEDBLOGFILES 1586431182000 error/postgresql.log.2020-04-09-11 4024 dwe@dwe:~/Documents/aws$ aws rds download-db-log-file-portion --db-instance-identifier dwe-pg --log-file-name error/postgres.log | tail -15 2020-04-09 11:19:46 UTC::@:[27607]:LOG: database system is shut down 2020-04-09 11:19:47.453 GMT [27773] LOG: skipping missing configuration file "/rdsdbdata/config/recovery.conf" 2020-04-09 11:19:47.453 GMT [27773] LOG: skipping missing configuration file "/rdsdbdata/config/recovery.conf" 2020-04-09 11:19:47 UTC::@:[27773]:LOG: database system is shut down Postgres Shared Memory Value: 35386589184 bytes 2020-04-09 11:19:47.482 GMT [27785] LOG: skipping missing configuration file "/rdsdbdata/config/recovery.conf" 2020-04-09 11:19:47.482 GMT [27785] LOG: skipping missing configuration file "/rdsdbdata/config/recovery.conf" 2020-04-09 11:19:47 UTC::@:[27785]:LOG: starting PostgreSQL 12.2 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.3 20140911 (Red Hat 4.8.3-9), 64-bit 2020-04-09 11:19:47 UTC::@:[27785]:LOG: listening on IPv4 address "0.0.0.0", port 5432 2020-04-09 11:19:47 UTC::@:[27785]:LOG: listening on IPv6 address "::", port 5432 2020-04-09 11:19:47 UTC::@:[27785]:LOG: listening on Unix socket "/tmp/.s.PGSQL.5432" 2020-04-09 11:19:47 UTC::@:[27785]:FATAL: could not map anonymous shared memory: Cannot allocate memory 2020-04-09 11:19:47 UTC::@:[27785]:HINT: This error usually means that PostgreSQL's request for a shared memory segment exceeded available memory, swap space, or huge pages. To reduce the request size (currently 35386589184 bytes), reduce PostgreSQL's shared memory usage, perhaps by reducing shared_buffers or max_connections. 2020-04-09 11:19:47 UTC::@:[27785]:LOG: database system is shut down
A bit strange is, that there is no recovery.conf in PostgreSQL 12 but AWS somehow still is referencing that somewhere.
So far for changing parameters. In the next post we’ll look at backup and restore.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)