We recently encountered an error at a customer’s site. Their Alfresco environment was behaving strangely.
Sometimes the search results worked, and sometimes they did not get the expected results.
The context
The environment is composed of 2 Alfresco7 nodes in cluster and 2 Solr 6.6 nodes load balanced (in active-active mode).
Sometimes the customer isn’t able to retrieve the document he created recently.
Investigation steps
Since we have load balancing in place, the first step is to confirm that everything is okay on the two nodes.
- I checked that Alfresco is running as expected. Nothing out of the ordinary; the processes are there and there are no errors in the log files and everything is green in the admin console.
- Then, I checked the alfresco-global.properties on both nodes to ensure the configuration is the same. We never know. I also checked the way we connect to Solr and confirmed that the load-balanced URL is being used.
- At this point, it is almost certain that the problem is with Solr. We will start by checking the administration console. Because we have load balancing, we must connect to each node individually and cannot use the URL in alfresco-global.properties.
- At first glance, everything seems fine, but a closer inspection of the Core Admin panel reveals a difference of several thousand “NumDocs” between the two nodes. These values may differ because they are internal Solr files. However, the discrepancy is too high in my opinion.
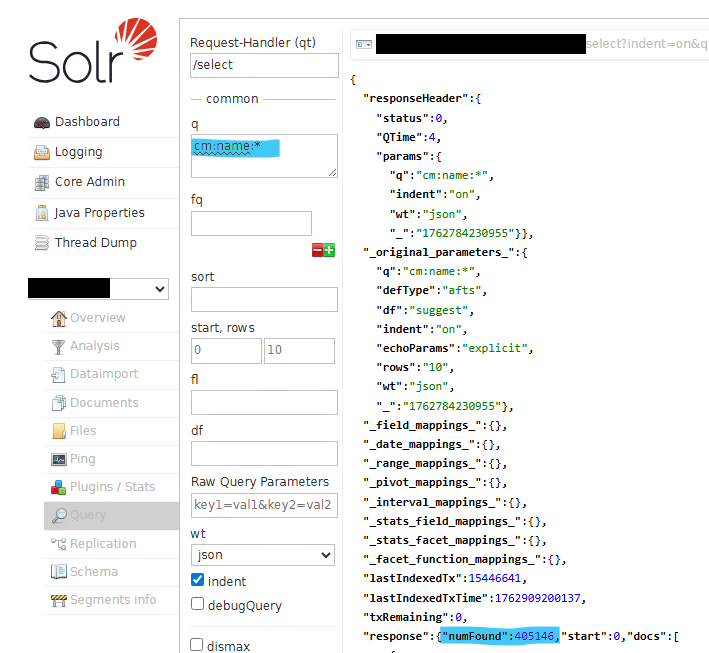
- How can this assumption be verified? Move to any core and run a query to list all the files (cm:name:*). On the first node, the query returns an error. On the second node, I received an answer similar to the one below:
- Now moving to the server where I have the error, in the logs there are errors like:
2025-11-10 15:33:32.466 ERROR (searcherExecutor-137-thread-1-processing-x:alfresco-3) [ x:alfresco-3] o.a.s.c.SolrCore null:org.alfresco.service.cmr.dictionary.DictionaryException10100009 d_dictionary.model.err.parse.failure
at org.alfresco.repo.dictionary.M2Model.createModel(M2Model.java:113)
at org.alfresco.repo.dictionary.M2Model.createModel(M2Model.java:99)
at org.alfresco.solr.tracker.ModelTracker.loadPersistedModels(ModelTracker.java:181)
at org.alfresco.solr.tracker.ModelTracker.<init>(ModelTracker.java:142)
at org.alfresco.solr.lifecycle.SolrCoreLoadListener.createModelTracker(SolrCoreLoadListener.java:341)
at org.alfresco.solr.lifecycle.SolrCoreLoadListener.newSearcher(SolrCoreLoadListener.java:139)
at org.apache.solr.core.SolrCore.lambda$getSearcher$15(SolrCore.java:2249)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at org.apache.solr.common.util.ExecutorUtil$MDCAwareThreadPoolExecutor.lambda$execute$0(ExecutorUtil.java:229)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:829)
Caused by: org.jibx.runtime.JiBXException: Error accessing document
at org.jibx.runtime.impl.XMLPullReaderFactory$XMLPullReader.next(XMLPullReaderFactory.java:293)
at org.jibx.runtime.impl.UnmarshallingContext.toStart(UnmarshallingContext.java:446)
at org.jibx.runtime.impl.UnmarshallingContext.unmarshalElement(UnmarshallingContext.java:2750)
at org.jibx.runtime.impl.UnmarshallingContext.unmarshalDocument(UnmarshallingContext.java:2900)
at org.alfresco.repo.dictionary.M2Model.createModel(M2Model.java:108)
... 11 more
Caused by: java.io.EOFException: input contained no data
at org.xmlpull.mxp1.MXParser.fillBuf(MXParser.java:3003)
at org.xmlpull.mxp1.MXParser.more(MXParser.java:3046)
at org.xmlpull.mxp1.MXParser.parseProlog(MXParser.java:1410)
at org.xmlpull.mxp1.MXParser.nextImpl(MXParser.java:1395)
at org.xmlpull.mxp1.MXParser.next(MXParser.java:1093)
at org.jibx.runtime.impl.XMLPullReaderFactory$XMLPullReader.next(XMLPullReaderFactory.java:291)
... 15 more- It looks like the problem is related to the model definition. We need to check if the models are still there in ../solr_data/models. The models are still in place, but one of them is 0 KB.
- So we need to force delete the empty file and restart Solr to force the model to be reimported.
After taking these actions, we reimported the model file and the errors in the logs disappeared. In the admin console, we can see NumDocs increasing again. When we re-run the query, we get a result.
Conclusion
At the end, this also highlights an important point: the need for monitoring! With adequate log monitoring, this error could have been spotted more quickly, resulting in a faster diagnosis. Don’t hesitate to ask us for more information, here.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GME_web-min-scaled.jpg)

![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MOP_web-min-scaled.jpg)