Introduction
“Make it simple.”
When you have to create a solution, design an architecture, you should always take the simplest path, this is often the better solution proven by field knowledge and experiences of not scalable patterns. Which means also that you should only add the necessary and required complexity to your solutions.
So while following this principle I tried to look for the simplest event driven design that I could find.
And here it is :
PG Source → Flink CDC → JDBC Sink → PG Data Mart
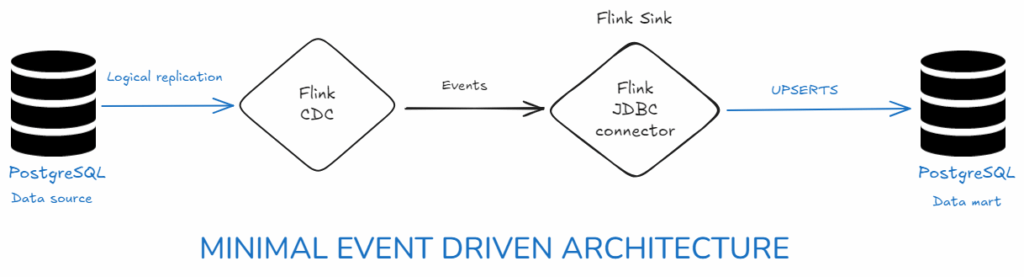
What each piece does :
- PostgreSQL (source)
Emits a change stream from the WAL using logical replication (wal_level=logical).
A publication defines which tables are replicated; a replication slot (one active reader per slot) holds WAL until the consumer confirms it. - Flink CDC source (Postgres)
A Flink table that reads from the publication/slot and turns WAL into a changelog stream (insert/update/delete).
Key options you’re using:scan.incremental.snapshot.enabled=true– non-blocking initial loadslot.name=...– binds the job to a specific slot- primary key in the table schema – lets downstream sinks do upserts
- Flink runtime
Runs a streaming job that:- Initial incremental snapshot: splits the table, bulk reads current rows, remembers an LSN.
- Catch-up + stream: replays WAL from that LSN and then tails new changes.
- Checkpoints: the slot LSN + operator state are stored on your S3/MinIO path, so restarts resume exactly from the last acknowledged point.
- JDBC sink (Postgres data mart)
Another Flink table. With a PRIMARY KEY defined, the connector performs UPSERT/DELETE semantics (e.g.,INSERT ... ON CONFLICT DO UPDATEin Postgres).
It writes in batches, flushes on checkpoints, and retries on transient errors. - PostgreSQL (data mart)
Receives the normalized upsert/delete stream and ends up with a 1:1 “current state” of the source tables (ideal for BI).
Why is this design is useful ?
- Near-real-time replication with transforms: you can filter, project, cleanse, deduplicate, join reference data, and even aggregate in Flink SQL before hitting the data mart—something native logical replication can’t do.
- Upserts keep the mart tidy: the JDBC sink writes the current state keyed by your PKs (perfect for reporting).
- Resilient: checkpoints + WAL offsets → automatic catch-up after failures/restarts.
- DB-friendly: WAL-based CDC has low OLTP impact compared to heavy ETL pulls.
LAB DEMO
Architecture of the LAB :
server1 (SRC) → PostgreSQL 17.6 (source) + Flink (jobs run here) : IP 172.19.0.4
server2 (SINKS) → PostgreSQL 17.6 (data mart) : IP 172.20.0.4
First we need data to transfer, here is a sample database that you can create yourself, additionally we also setup the PostgreSQL instance :
# Execute on server1 only
sudo -u postgres psql -c "ALTER SYSTEM SET wal_level='logical';"
# Increase the number of concurrent replication connections allowed.
sudo -u postgres psql -c "ALTER SYSTEM SET max_wal_senders=10;"
# Increase the number of replication slots the server can support.
sudo -u postgres psql -c "ALTER SYSTEM SET max_replication_slots=10;"
# On both servers, modify the Host-Based Authentication file to allow connections from each others.
echo "host all all 127.0.0.1/32 trust" | sudo tee -a /etc/postgresql/17/main/pg_hba.conf
echo "host all all 172.19.0.4/32 scram-sha-256" | sudo tee -a /etc/postgresql/17/main/pg_hba.conf
echo "host all all 172.20.0.4/32 scram-sha-256" | sudo tee -a /etc/postgresql/17/main/pg_hba.conf
# Restart the PostgreSQL service to apply all configuration changes.
sudo systemctl restart postgresql
sudo -u postgres createdb logistics_src
sudo su - postgres
# Execute a multi-statement SQL block to define and seed the schema.
psql -U postgres -d logistics_src <<'SQL'
CREATE SCHEMA logistics;
CREATE TABLE logistics.customers (
customer_id bigserial PRIMARY KEY,
name text NOT NULL,
city text,
email text UNIQUE
);
CREATE TABLE logistics.products (
product_id bigserial PRIMARY KEY,
sku text UNIQUE NOT NULL,
name text NOT NULL,
list_price numeric(12,2) NOT NULL
);
CREATE TABLE logistics.orders (
order_id bigserial PRIMARY KEY,
customer_id bigint NOT NULL REFERENCES logistics.customers(customer_id),
status text NOT NULL DEFAULT 'NEW',
order_ts timestamptz NOT NULL DEFAULT now()
);
CREATE TABLE logistics.order_items (
order_id bigint NOT NULL REFERENCES logistics.orders(order_id),
product_id bigint NOT NULL REFERENCES logistics.products(product_id),
qty int NOT NULL,
unit_price numeric(12,2) NOT NULL,
PRIMARY KEY(order_id, product_id)
);
CREATE TABLE logistics.inventory (
product_id bigint PRIMARY KEY REFERENCES logistics.products(product_id),
on_hand int NOT NULL DEFAULT 0
);
CREATE TABLE logistics.shipments (
shipment_id bigserial PRIMARY KEY,
order_id bigint NOT NULL REFERENCES logistics.orders(order_id),
carrier text,
shipped_at timestamptz,
status text
);
-- Seed initial data
INSERT INTO logistics.customers(name,city,email)
SELECT 'Customer '||g, 'City '|| (g%10), 'c'||g||'@example.com'
FROM generate_series(1,200) g;
INSERT INTO logistics.products(sku,name,list_price)
SELECT 'SKU-'||g, 'Product '||g, (random()*90+10)::numeric(12,2)
FROM generate_series(1,500) g;
INSERT INTO logistics.inventory(product_id,on_hand)
SELECT product_id, (random()*100)::int
FROM logistics.products;
-- Create 100 orders
WITH o AS (
INSERT INTO logistics.orders(customer_id,status)
SELECT (floor(random()*200)+1)::int, 'NEW' -- customers 1..200
FROM generate_series(1,100)
RETURNING order_id
)
-- For each order, choose 2 distinct products and insert items
INSERT INTO logistics.order_items(order_id, product_id, qty, unit_price)
SELECT o.order_id,
p.product_id,
(floor(random()*5)+1)::int AS qty, -- qty 1..5
p.list_price
FROM o
CROSS JOIN LATERAL (
SELECT pr.product_id, pr.list_price
FROM logistics.products pr
ORDER BY random()
LIMIT 2
) AS p;
SQL
psql -U postgres -d logistics_src -c "ALTER ROLE postgres IN DATABASE logistics_src
SET search_path = logistics, public;"
postgres@LAB-CDC-SRC:~$ psql -U postgres -d logistics_src -c "ALTER ROLE postgres IN DATABASE logistics_src
SET search_path = logistics, public;"
ALTER ROLE
postgres@LAB-CDC-SRC:~$ psql
psql (17.6 (Ubuntu 17.6-1.pgdg24.04+1))
Type "help" for help.
postgres=# \l
List of databases
Name | Owner | Encoding | Locale Provider | Collate | Ctype | Locale | ICU Rules | Access privileges
---------------+----------+----------+-----------------+---------+---------+--------+-----------+-----------------------
logistics_src | postgres | UTF8 | libc | C.UTF-8 | C.UTF-8 | | |
postgres | postgres | UTF8 | libc | C.UTF-8 | C.UTF-8 | | |
template0 | postgres | UTF8 | libc | C.UTF-8 | C.UTF-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | libc | C.UTF-8 | C.UTF-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
(4 rows)
postgres=# \c logistics_src
You are now connected to database "logistics_src" as user "postgres".
logistics_src=# \dt
List of relations
Schema | Name | Type | Owner
-----------+-------------+-------+----------
logistics | customers | table | postgres
logistics | inventory | table | postgres
logistics | order_items | table | postgres
logistics | orders | table | postgres
logistics | products | table | postgres
logistics | shipments | table | postgres
(6 rows)
logistics_src=# SELECT count(*) FROM logistics.orders;
SELECT count(*) FROM logistics.order_items;
count
-------
700
(1 row)
count
-------
1100
(1 row)
## Here I created a slot per table on my source
postgres=# SELECT slot_name, active, confirmed_flush_lsn FROM pg_replication_slots;
SELECT pubname FROM pg_publication;
slot_name | active | confirmed_flush_lsn
------------------------+--------+---------------------
flink_order_items_slot | f | 0/20368F0
flink_orders_slot | f | 0/20368F0
(2 rows)
pubname
---------
(0 rows)
postgres=#
On my target data mart I created the empty structure :
logistics_dm=#
SELECT count(*) FROM datamart.orders;
SELECT count(*) FROM datamart.order_items;
count
-------
0
(1 row)
count
-------
0
(1 row)
logistics_dm=#
Then we can start Flink :
adrien@LAB-CDC-SRC:~/flink-1.20.2$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host LAB-CDC-SRC.
Starting taskexecutor daemon on host LAB-CDC-SRC.
Verify that your Flink UI is up by checking the URL http://127.0.0.1:8081
In my case I created a custom config file to handle some other aspects of my LAB like the Hudi and S3 part that you can skip. The important point in the config is more related to task manager and memory settings for the scheduler :
adrien@LAB-CDC-SRC:~/flink-1.20.2$ cat conf/flink-conf.yaml
jobmanager.rpc.address: localhost
# Web/API
rest.address: 0.0.0.0
# Memory (required by 1.20 to be set explicitly)
jobmanager.memory.process.size: 1200m
taskmanager.memory.process.size: 1600m
taskmanager.numberOfTaskSlots: 8
# Allow multiple small jobs at once
parallelism.default: 1 # so each job can start with 1 slot by default
jobmanager.scheduler: adaptive
# Checkpoint/savepoint locations (use MinIO so they survive restarts)
state.checkpoints.dir: s3a://flink/checkpoints
state.savepoints.dir: s3a://flink/savepoints
execution.checkpointing.interval: 10 s
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
# Optional resilience
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 10
restart-strategy.fixed-delay.delay: 5 s
# Prefer parent loader (helps with some connector deps)
classloader.resolve-order: parent-first
classloader.check-leaked-classloader: false
# S3A to MinIO (Hadoop FS)
s3.endpoint: http://172.20.0.4:9000
s3.path.style.access: true
s3.access.key: admin
s3.secret.key: adminadmin
s3.connection.ssl.enabled: false
#s3.impl: org.apache.hadoop.fs.s3a.S3AFileSystem
#s3.aws.credentials.provider: org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider
# optional, handy for labs
execution.checkpointing.interval: 10 s
env.java.opts: --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED -Djdk.attach.allowAttachSelf=true
adrien@LAB-CDC-SRC:~/flink-1.20.2$
Then we start the SQL client,
adrien@LAB-CDC-SRC:~/flink-1.20.2$ ./bin/sql-client.sh
▒▓██▓██▒
▓████▒▒█▓▒▓███▓▒
▓███▓░░ ▒▒▒▓██▒ ▒
░██▒ ▒▒▓▓█▓▓▒░ ▒████
██▒ ░▒▓███▒ ▒█▒█▒
░▓█ ███ ▓░▒██
▓█ ▒▒▒▒▒▓██▓░▒░▓▓█
█░ █ ▒▒░ ███▓▓█ ▒█▒▒▒
████░ ▒▓█▓ ██▒▒▒ ▓███▒
░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░
▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒
███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒
░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒
███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░
██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓
▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒
▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒
▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█
██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █
▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓
█▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓
██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓
▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒
██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒
▓█ ▒█▓ ░ █░ ▒█ █▓
█▓ ██ █░ ▓▓ ▒█▓▓▓▒█░
█▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█
██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓
▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██
░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓
░▓██▒ ▓░ ▒█▓█ ░░▒▒▒
▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░
______ _ _ _ _____ ____ _ _____ _ _ _ BETA
| ____| (_) | | / ____|/ __ \| | / ____| (_) | |
| |__ | |_ _ __ | | __ | (___ | | | | | | | | |_ ___ _ __ | |_
| __| | | | '_ \| |/ / \___ \| | | | | | | | | |/ _ \ '_ \| __|
| | | | | | | | < ____) | |__| | |____ | |____| | | __/ | | | |_
|_| |_|_|_| |_|_|\_\ |_____/ \___\_\______| \_____|_|_|\___|_| |_|\__|
Welcome! Enter 'HELP;' to list all available commands. 'QUIT;' to exit.
Command history file path: /home/adrien/.flink-sql-history
-- Set the checkpointing interval for the SQL client session.
-- While configured globally in flink-conf.yaml, setting it here ensures it applies.
SET 'execution.checkpointing.interval' = '10s';
-- =============================================================================
-- DEFINE CDC SOURCE TABLES
-- =============================================================================
-- This table definition maps to the 'logistics.orders' table in PostgreSQL.
-- The 'postgres-cdc' connector is used to stream changes.
SET 'execution.checkpointing.interval' = '10s';
CREATE TABLE src_orders (
order_id BIGINT,
customer_id BIGINT,
status STRING,
order_ts TIMESTAMP(3),
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = '172.19.0.4',
'port' = '5432',
'username' = 'postgres',
'password' = 'your_postgres_password',
'database-name' = 'logistics_src',
'schema-name' = 'logistics',
'table-name' = 'orders',
'slot.name' = 'flink_orders_slot',
'decoding.plugin.name' = 'pgoutput',
'scan.incremental.snapshot.enabled' = 'true'
);
CREATE TABLE src_order_items (
order_id BIGINT,
product_id BIGINT,
qty INT,
unit_price DECIMAL(12,2),
PRIMARY KEY (order_id, product_id) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = '172.19.0.4',
'port' = '5432',
'username' = 'postgres',
'password' = 'your_postgres_password',
'database-name' = 'logistics_src',
'schema-name' = 'logistics',
'table-name' = 'order_items',
'slot.name' = 'flink_order_items_slot',
'decoding.plugin.name' = 'pgoutput',
'scan.incremental.snapshot.enabled' = 'true'
);
CREATE TABLE dm_orders (
order_id BIGINT,
customer_id BIGINT,
status STRING,
order_ts TIMESTAMP(3),
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:postgresql://172.20.0.4:5432/logistics_dm',
'table-name' = 'datamart.orders',
'username' = 'postgres',
'password' = 'your_postgres_password',
'driver' = 'org.postgresql.Driver'
);
CREATE TABLE dm_order_items (
order_id BIGINT,
product_id BIGINT,
qty INT,
unit_price DECIMAL(12,2),
PRIMARY KEY (order_id, product_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:postgresql://172.20.0.4:5432/logistics_dm',
'table-name' = 'datamart.order_items',
'username' = 'postgres',
'password' = 'your_postgres_password',
'driver' = 'org.postgresql.Driver'
);
INSERT INTO dm_orders SELECT * FROM src_orders;
INSERT INTO dm_order_items SELECT * FROM src_order_items;
So here we just declared the source tables and the data mart tables, note the connector type.
Once the tables are declare in Flink you can then start the pipeline with the INSERT INTO statements.
At the end you should get something like this in the sql_client.sh :
Flink SQL> [INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 1e776162f4e23447ed5a9546ff464a61
Flink SQL> [INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 14ea0afbf7e2fda44efc968c189ee480
And in Flink :
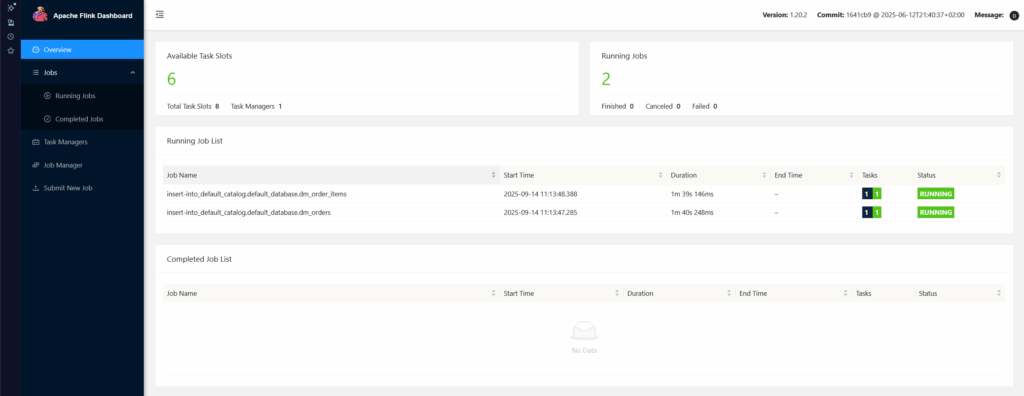
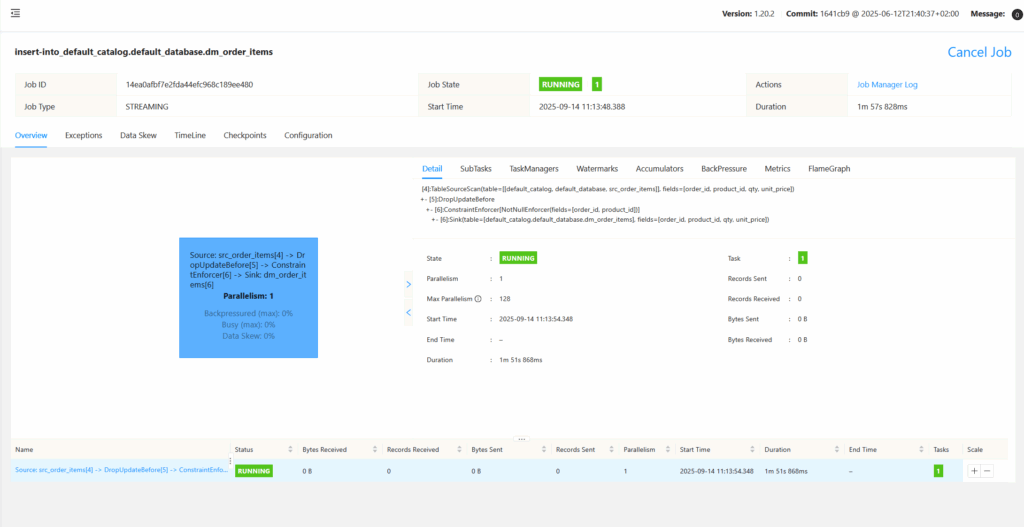
Then verify that on the target data mart the tables are now populated :
postgres=# \c logistics_dm
You are now connected to database "logistics_dm" as user "postgres".
logistics_dm=#
SELECT count(*) FROM datamart.orders;
SELECT count(*) FROM datamart.order_items;
count
-------
700
(1 row)
count
-------
1100
(1 row)
logistics_dm=# select * from order_items limit 5;
order_id | product_id | qty | unit_price | discount
----------+------------+-----+------------+----------
224 | 223 | 4 | 15.44 | 0.00
96 | 94 | 1 | 53.91 | 0.00
689 | 143 | 3 | 70.71 | 0.00
290 | 223 | 3 | 15.44 | 0.00
93 | 191 | 2 | 95.85 | 0.00
(5 rows)
logistics_dm=# select * from orders limit 5;
order_id | customer_id | status | order_ts | channel
----------+-------------+--------+-------------------------------+---------
310 | 163 | NEW | 2025-09-09 14:36:47.247234+00 |
305 | 69 | NEW | 2025-09-09 14:36:47.247234+00 |
304 | 14 | NEW | 2025-09-09 14:36:47.247234+00 |
303 | 122 | NEW | 2025-09-09 14:36:47.247234+00 |
302 | 9 | NEW | 2025-09-09 14:36:47.247234+00 |
(5 rows)
And this is it, we did setup the of the minimal event-driven architecture.
End-to-end flow (what happens when you “INSERT INTO dm_* SELECT * FROM src_*”)
- Flink CDC attaches to the slot and (if configured) creates/uses the publication.
- It takes a consistent snapshot of
orders/order_items, while buffering concurrent WAL changes. - Once snapshot is done, it emits the buffered changes and continues streaming new WAL records.
- The JDBC sink receives a relational changelog:
INSERT→INSERT … ON CONFLICT DO UPDATE(upsert)UPDATE→ treated as upsertDELETE→DELETE … WHERE pk = ?
- Checkpoints coordinate the CDC source offsets with the sink flush so recovery doesn’t duplicate effects. With upserts, the pipeline is effectively-once even if a retry happens.
Operational knobs that matter
- One slot per independent reader (or a single job fan-out via Statement Set).
- Checkpointing (you’ve set it):
execution.checkpointing.interval=10 s+ S3 paths forstate.checkpoints.dir/state.savepoints.dir. - Target DDL: create the DM tables up front with PRIMARY KEY to enable upserts.
- Throughput: increase job/connector parallelism, adjust JDBC sink batch size/interval if needed (defaults are usually fine for this lab).
- DDL changes on the source: Postgres logical decoding does not emit DDL → when schemas change, redeploy the Flink table DDL (and adjust the target tables). Use Liquibase/Flyway to manage that cleanly.
Limitations to keep in mind
- PK required for clean upserts/deletes. Without it, the JDBC sink would just append.
- Pros (vs. PostgreSQL logical replication)
- DDL: manual coordination (expand/contract) is required.
- Slots: one active consumer per slot; multiple slots can increase WAL retention if a reader lags or is stopped.
- Backpressure: a slow data mart will throttle the job; watch Flink backpressure metrics and tune JDBC batching/parallelism.
Pros of this design
- Transform while you move: filter, project, join, enrich, aggregate, de-duplicate, derive SCD logic—before data lands in the target.
- Fan-out: the same CDC stream can drive many targets (multiple PG DBs, ClickHouse, Elasticsearch, etc.).
- Decoupling & safety: backpressure, retries, checkpointed state, and rate-limiting protect the source and the target; you can shape load to the DM.
- Schema mediation: implement expand/contract, rename mapping, default values—logical replication needs the same schema on both sides.
- Non-PG targets: works when your sink isn’t Postgres (or not only Postgres).
- Observability: Flink UI and metrics on lag, checkpoints, failures, couple it with already proven Prometheus exporters.
Cons
- More moving parts: Flink cluster + connectors to operate.
- Latency a bit higher: seconds (checkpoint cadence, batching) instead of sub-second WAL apply.
- DDL isn’t automatic: Postgres logical decoding doesn’t emit DDL; you still manage schema changes (expand/contract + redeploy).
- Throughput tuning: JDBC upserts can bottleneck a single DB; you tune parallelism and flush/batch settings.
When logical replication is better
- You just need a near-real-time 1:1 copy PG→PG, no transforms, same schema, and lowest latency with minimal ops.
- You’re okay with subscriber-side work (indexes/views) and whole-table subscription (no row-level filtering).
When should you “upgrade” with a Hudi sink (data lake)
Add Hudi when you need things a database replica can’t give you:
- History & replayability: keep the raw truth (Bronze) cheaply; rebuild downstream tables any time.
- Upserts/deletes at scale on files: CDC-friendly MOR/COW tables.
- Time travel & incremental pulls: audits, backtests, point-in-time reprocessing.
- Many heterogeneous consumers: BI + ML + ad-hoc engines (Trino/Spark/Presto) without re-extracting from OLTP.
- Big volumes: storage and compute scale independently; you can compaction/cluster off-peak.
- Scale compute and storage independently.
Trade-off: more infra (S3/MinIO + compaction), higher “cold” query latency than a hot DB, and you still materialize serving tables for apps.
What I don’t like with this design :
- Java based : I don’t like to handle Java issues, runtime and versions. I am not a developer and those kinds of this should be packaged in a way that it makes them run fast and easy. This open source version and setup is not that user-friendly and requires deep knowledge of the tool, but realistically not that much more than any other tool that would do similar things. Additionally, if your are going to run this in production there is a high likelihood that your are going to use Kubernetes which is going to solve those issues and offer scalability.
- The versions dependencies : I did figure out the hard way that not all latest version of all packages used are compatible with each other. In the open source world some projects sometimes need to catch up in development. Here I need to use Flink 1.20.2 to have CDC working with HUDI for example and because I want to use both JDBC connector and HUDI Sink I had to downgrade the entire stack. So be careful Flink 1.20 is the LTS version so this is fine but if you want to use the latest feature of the stable version you might want to check that first.
- Cloud : this operational complexity for setup and management is handle on the cloud hence the strong argument to go for it appart from the obvious data sensitivity issue but that last part is more a labelling and classification issue than really a Flink usage argument. If your company is using not taking leverage of cloud solution because it is afraid of data loss, this is a high indicator of a lack of maturity in that area rather than a technical limitation.
Additional notes : this setup is not meant for production, this is a simple showcase for lab purpose that you can easily reproduce, here there is not persistence (if you restart the Flink processes your pipeline are lost), if you want a production ready setup refer to the official documentation and look for Kubernetes installations probably : Introduction | Apache Flink CDC.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2025/03/OBA_web-scaled.jpg)