
It has been a long time since the last Oracle 12c Optimizer article, but this one is the last on the series about customer issues in Oracle 11g. The goal of that series is to show how the new version 12c of Oracle Database helps solving these issues. This blog posting focuses on a well know Oracle behavior when gathering histograms on a varchar2 column.
The three cases have been presented during the session “Solving critical customer issues with the Oracle 12c Optimizer” at the Oracle Open World 2013, the UKOUG Tech13 and the dbi’s 12c appetizers.
Context
The application is a well-known DMS (Document Management System) where the database hosts a repository whereas the documents are stored as files on a filesystem.
In that application, there is a table FOLDER used to store the physical location of a file associated to a document id. To simplify, in my lab I recreated the table with only two columns: R_OBJECT_ID representing the document id and R_FOLDER_PATH representing the filesystem path where the document is stored.
The application regularly checks the document id associated to a provided path. On the table, there is an existing index on the R_FOLDER_PATH column to speed up the process.
![]()
Let’s have a look on the data distribution at customer site:
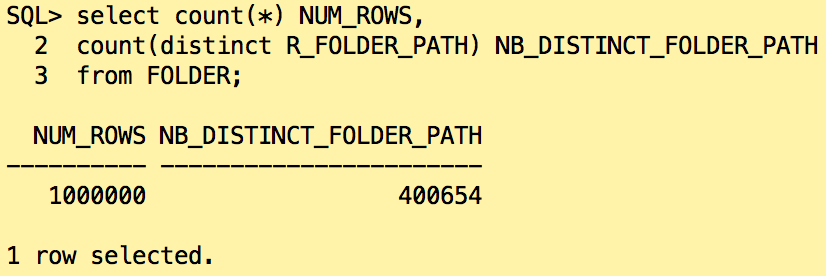
On 1 million of documents, there are 400654 unique paths and 599346 documents without path. So we can say that each document has a unique path on the filesystem otherwise the path is NULL.
If we have a closer look on the paths stored in that table, we can notice that the beginning of the paths are quite similar due to the naming convention used for the folders. We check the number of paths that begin with the same first 32 characters with the following query:
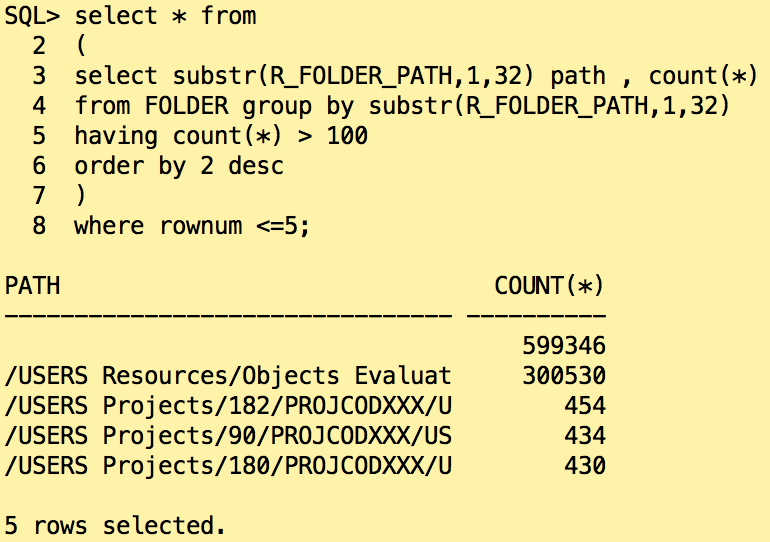
We can see that more than 300 000 documents on 1 million starts with the same string. What is the impact of such data distribution?
Behavior in 11g
A simple query is used to get the R_OBJECT_ID associated to a provided R_FOLDER_PATH:
![]()
We execute the statement without statistics on the table. The value of the bind variable p0 is set to a path starting with the string ‘/USERS Resources/Objects Evaluation/’.
Let’s have a look on the execution plan for that statement:
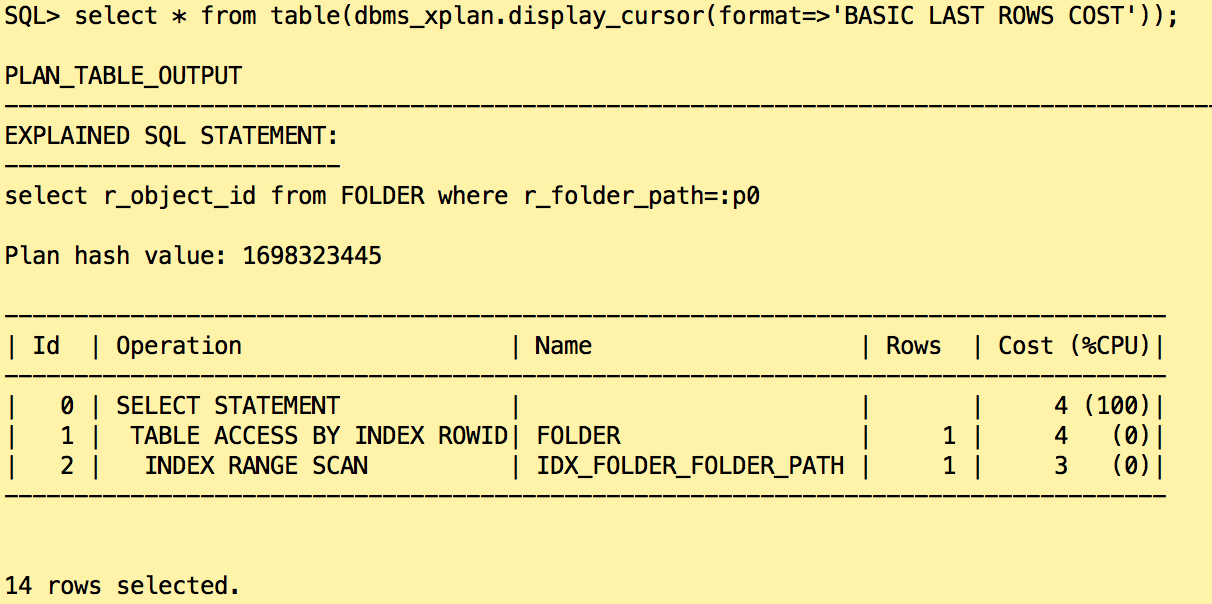
The estimated cardinality is correct, only one row is returned from the table FOLDER and the index is used. The statement completed quickly.
Now, by default during the night Oracle will collect statistics on that table. To simulate the process, we start the procedure gather_table_stats to collect statistics on the table.
![]()
We kept all default value for the statistics gathering, we can now check the column R_FOLDER_PATH statistics:

The column has been involved in an equality predicate, Oracle estimated that there is a data skew and that a histogram can give more information on the data distribution.
As Oracle found more than 254 distinct values, it created an Height balanced histogram with 254 buckets.
Now, we can restart the same statement to check the impact of the histogram on the cardinality. To avoid re-using the same cursor and force a new parse, a comment is added to the statement. Again, the value of p0 is set to a path starting with the string ‘/USERS Resources/Objects Evaluation/’
![]()
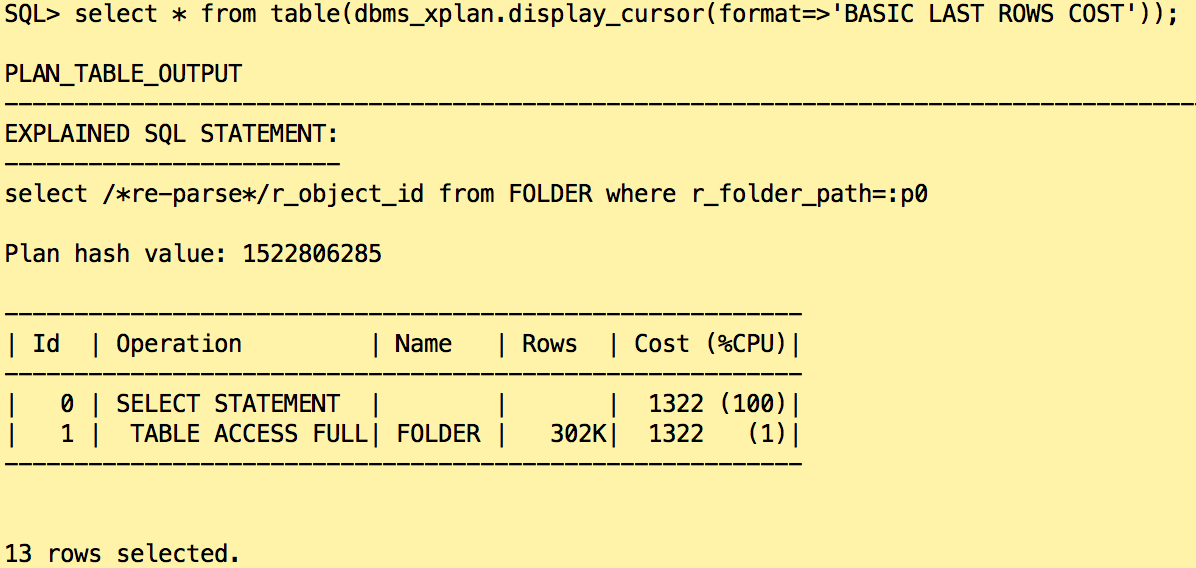
Using the histogram, Oracle estimated that more than 300 000 documents match the filter. So instead of using the index, Oracle uses a FULL TABLE SCAN and reads the whole table.
Why Oracle estimated more than 300 000 rows using the histogram? When Oracle gathers an histogram on a varchar2 column, it reads the first 32 bytes only. All paths starting with the string ‘/USERS Resources/Objects Evaluat’ are considered as identical and fall in the same bucket. In the table, we do have more than 300 000 rows starting with that way.
Behavior in 12c
If we run the same test on an Oracle Database 12c, we have the same results for the first execution of the statement. During the first execution, the estimation is only 1 row is returned and the index is used.
But what are the column statistics after running the procedure gather_table_stats?

That time, there is no histogram on the column R_FOLDER_PATH. If we start again the statement in the same way as in Oracle 11g with a comment to force a new parse.
![]()
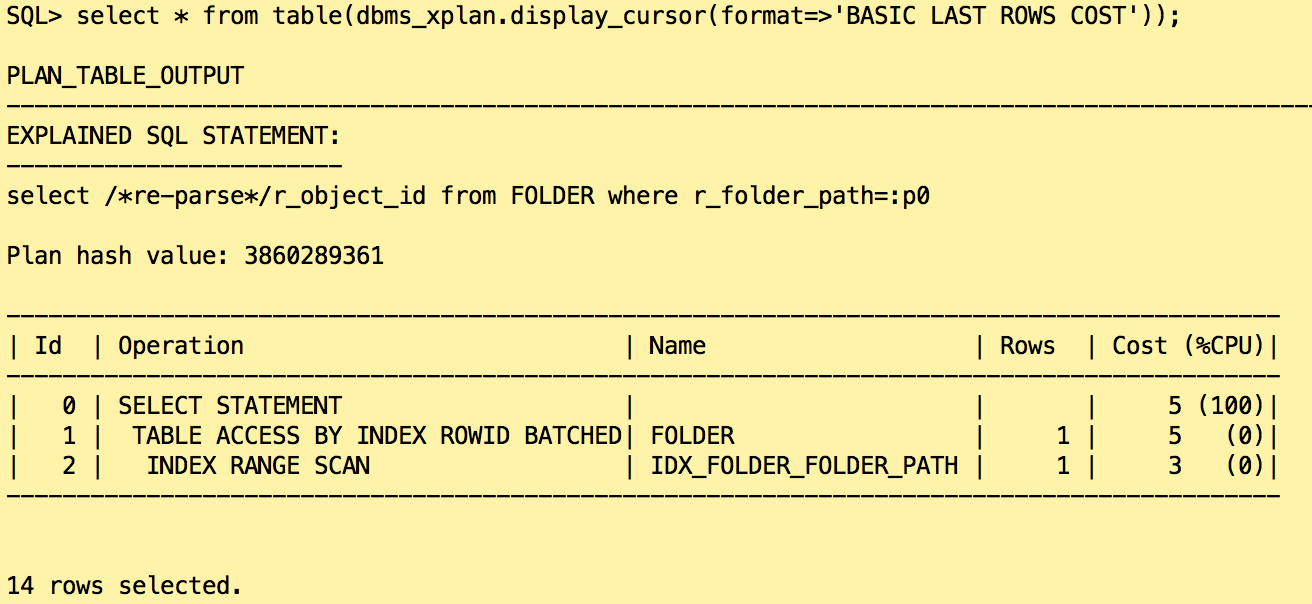
Without histogram, the cardinality stays to 1 row returned. It allows Oracle keeping the execution plan using the index.
You can download the scripts to replay the demo just following the link: Scripts_Histogram_Varchar2.zip
Conclusion
That issue occurred on a production system with 10 millions of rows in the table after the automatic job gathered the statistics on that table FOLDER. Using a FULL TABLE SCAN introduced a significant bad impact on the application performance. The only way to solve the issue was to delete the histogram and add a table preference to prevent Oracle from gathering histogram on that column.
The new way of gathering histogram in Oracle Database 12c allows solving that issue without the need of custom table preferences.
In newer releases, Oracle improves the statistics gathering in order to get better cardinalities and produce better execution plans.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/11/NIJ-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/OLS_web-min-scaled.jpg)