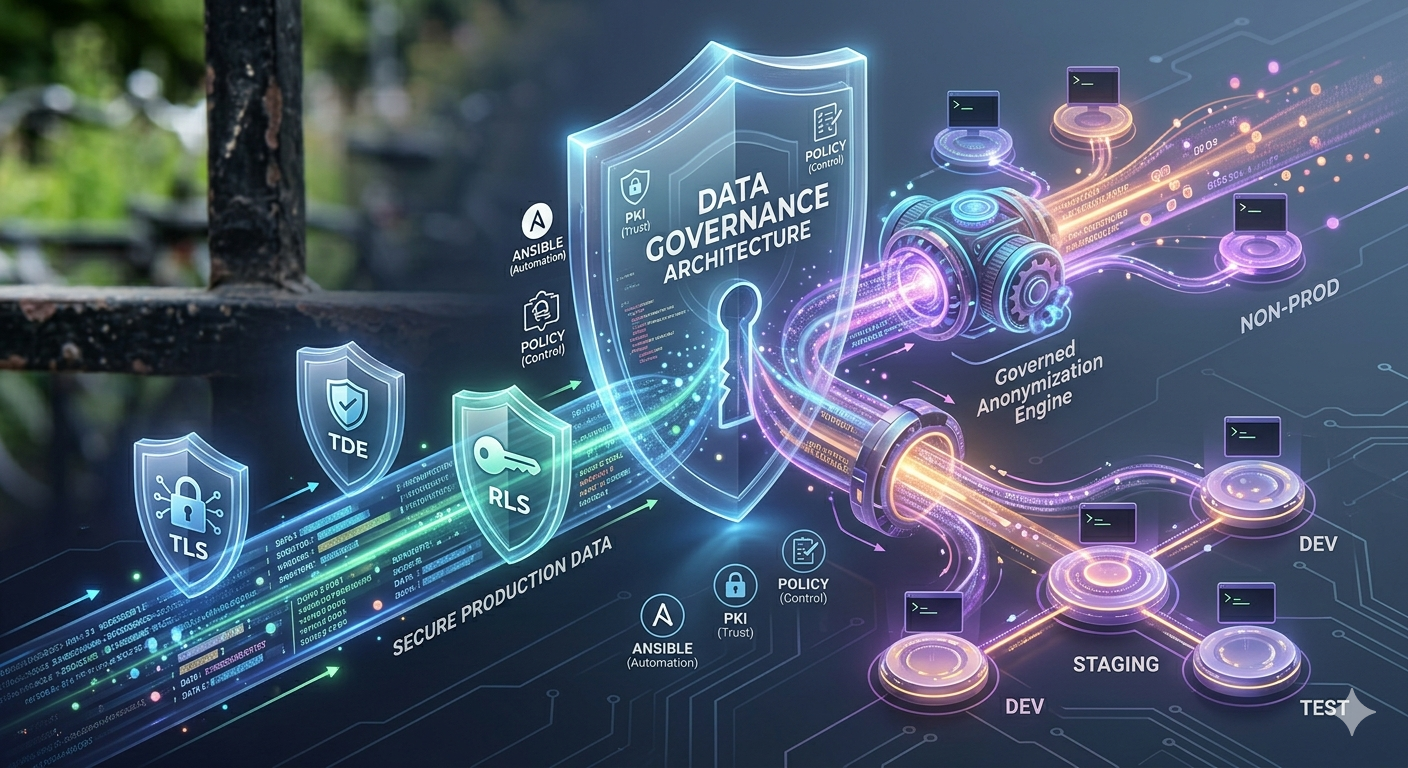
The Multi-Layered Threat: Why One Tool is Never Enough
We’ve all left the key in our bike lock at least once. This simple human oversight makes the heaviest chain irrelevant and we often see the exact same logic applied to data environments. Most organizations spend months hardening their production core but leave the keys in the locks of the dev and staging systems that sit right next to it.
The numbers back this up. While 91% of organizations are concerned about their exposure across lower environments, a staggering 86% still allow data compliance exceptions in non-production. This gap between concern and action has real consequences: more than half of these organizations have already experienced a breach or audit failure in their testing and development systems (PR Newswire).
Effective security is rarely a single-layer problem. Between the stolen backup that lands in the wrong hands, the analyst running a SELECT on a table they probably shouldn’t see, and the packet quietly crossing an unsecured network segment, the attack surface is wide, and no single mechanism covers it all.
Transport Layer Security (TLS), Transparent Data Encryption (TDE), symmetric encryption, dynamic masking, row-level security, data anonymization: for most RDBMS, the options exist and they work. Most teams already have access to at least one of them. The real challenge isn’t finding a solution; it’s understanding what each one actually protects, where it breaks down, and whether it survives contact with a production environment.
Shadow Environments: The Weakest Link in Your Data Chain
Here is the uncomfortable truth: non-production environments are often where security policies are quietly buried. It starts with a backup restored without encryption, or real customer data seeding a dev database “just for a quick test“.
The fundamental problem is that most protections assume a controlled environment. Encryption can be bypassed by someone with the right credentials. Masking can be misconfigured. Row-level security doesn’t help much when the whole database is sitting on a developer’s laptop.
Technical Trade-offs: Finding Your Strategic Fit
To make this reasoning concrete, the table below maps six core techniques against the operational criteria that define their success. The goal isn’t to pick a favorite tool, but to identify which combination actually addresses your specific vulnerabilities.
| Physical File Theft | Read Access (SELECT) | Network Sniffing | Performance Impact | Granularity | Applicable in Prod (live data) | Applicable in DEV | |
| TLS | ❌ | ❌ | ✅ | ✅ | Data packet | ✅ | ✅ |
| TDE | ✅ | ❌ | ❌ | ✅ | Column Tablespace Datafile | ✅ | ⚠️ |
| Symmetric encryption (applicative) | ✅ | ✅ | ✅ | ❌ | Field Value | ✅ | ✅ |
| Dynamic Masking | ❌ | ✅ | ❌ | ✅ | Column | ✅ | ✅ |
| Row-level security | ❌ | ✅ | ❌ | ✅ | Row | ✅ | ✅ |
| Data anonymization | ✅ | ✅ | ✅ | ✅ | Field Column | ❌ | ✅ |
- TLS protects data in motion. The moment a packet leaves a server, TLS ensures anyone intercepting it sees encrypted noise. What it doesn’t do is equally important: it has no opinion about who queries your database or what’s stored on disk. Once the data arrives, TLS’s job is done.
TLS is now the industry standard for securing data in motion.
(SQL Server technical blog about TLS here) - TDE encrypts the physical files that make up your database (data files, log files, backups), so that anyone who gets their hands on them without the encryption key can’t read them. The performance impact is a negligible overhead; in fact, Microsoft for example enables TDE by default for all its cloud-based databases.
(PostgreSQL technical blog about TDE here)
However, deploying TDE in development is a security best practice, but it quickly becomes an operational nightmare for environment refreshes, especially if you want to use distinct certificates to avoid leaking production secrets into lower environments. - Symmetric encryption is field-level encryption applied directly in the application layer. Unlike TDE, it survives a legitimate SELECT; even a user with full read access sees ciphertext unless they hold the applicative key. The tradeoff is performance: encrypting and decrypting at scale adds up quickly.
(MongoDB technical blog about Client-side Field Level Encryption here) - Dynamic masking doesn’t encrypt anything. It intercepts query results and replaces sensitive values with masked equivalents based on the user’s role. Fast, lightweight, zero application changes required. The catch: it only controls what’s displayed, not what’s stored. A user with sufficient privileges can bypass it entirely.
(SQL Server technical blog about dynamic masking here) - Row-Level Security enforces access at the row level directly inside the database engine. Users see only the rows they’re allowed to see, regardless of how the query is written. No application changes, no trust placed in the calling layer. The policy lives in the database and applies universally.
(Oracle technical blog about Virtual Private Database here) - Data anonymization doesn’t protect sensitive data, it eliminates it. Real values are replaced with realistic but fictional equivalents (synthetic data), permanently and irreversibly. No encryption key to steal, no masking rule to bypass. Whatever leaks simply isn’t sensitive anymore. This is why anonymization is the only control that makes unconditional sense in non-production environments. A stolen backup, a misconfigured SELECT, a sniffed packet: none of it matters if the data was anonymized before it ever reached a staging environment. We covered how to implement it in practice in a previous post
Ownership Gaps: The Security No Man’s Land
We are shifting from a technical challenge to a human and organizational one. The security landscape moves so fast that the struggle of mastering every layer has become overwhelming.
This complexity is where governance goes to die. Infrastructure teams build the walls, developers write the code, and DBAs manage the house, but the accountability for the data itself often falls through the cracks. The most dangerous gap isn’t a missing feature; it’s the absence of a governance model strong enough to stop the game of hot potato and force a cross-domain ownership of security.
The CISO’s role in this landscape is not to master every technical layer, it is to force the question of ownership into the open. Who signs off on what data enters a non-production environment? Who is accountable when a dev database is restored without encryption? Who audits that masking policies are still effective after a release?
Without explicit answers to these questions, security becomes a game of assumptions. Every team assumes another layer is holding. And the gaps compound silently, until they don’t.
From Handcrafted Scripts to Enterprise Platforms
Every technique in this table can be implemented on a spectrum, from a carefully written script to a fully automated enterprise solution. The right choice depends on your scale, your team, and how much operational overhead you can realistically absorb.
- TLS certificate deployment: you can generate and rotate certificates manually, instance by instance. Or you can automate the entire lifecycle using Ansible against an internal PKI with a consistent and auditable way that is invisible to the teams consuming it. The security outcome is identical; the operational cost is not.
- Data anonymization: a custom script that detects PII columns and replaces values with masked data works well at small scale. The challenge appears when your data spans multiple database engines (SQL Server, Oracle, PostgreSQL, …) and when anonymized values need to remain consistent across foreign keys and referential constraints. Replacing a customer ID in one table while leaving it intact in another isn’t anonymization, it’s a GDPR incident waiting to happen. Solutions like Delphix Continuous Compliance handle cross-DBMS consistency, constraint awareness, and sensitive field detection out of the box, turning a fragile hand-rolled process into a governed, repeatable and auditable one.
- Dynamic masking and row-level security: defining a handful of policies manually in SSMS is perfectly reasonable for a contained environment. Automating policy deployment across environments and instances is a different challenge entirely. It is a level of scale where ad-hoc scripts quickly become a liability.
Conclusion: Moving Beyond Security by Accident
Security is not a one-time project. It is an operational discipline that requires the same rigor in a developer’s sandbox as it does in production, and that rigor has to be enforced by design, not by goodwill.
Most breaches in non-production environments don’t happen because a tool failed. They happen because nobody owned the decision to use it in the first place.
At dbi services, we help organizations move from fragile, handcrafted scripts to governed, auditable architectures across every environment, every database engine, and every team.
Because under GDPR, one incident is all it takes to make ownership everyone’s problem.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/05/martin_bracher_2048x1536.jpg)