Introduction
In the first part of this RAG series, we established the fundamentals of Naive RAG with dense vector embeddings on PostgreSQL using pgvector. That foundation works well for conceptual queries, but production systems quickly reveal a limitation: pure semantic search misses exact matches like you would have with like or Full-text searches. When someone searches for “PostgreSQL 17 performance improvements,” pure vector search might return general performance topics while completely missing the specific version number. This is where hybrid search helps—combining the semantic understanding of dense embeddings with the precision of traditional keyword search.
We will explore hybrid sparse-dense search implementation with PostgreSQL and pgvector, diving a bit into the mathematics behind score fusion, practical implementation patterns using the pgvector_RAG_search_lab repository, and re-ranking techniques that can boost retrieval accuracy by 15-30%. We are building on the Wikipedia dataset (25,000 articles) from the previous post, but this time we will critically examine our embedding choice and optimization strategies. The aim being for you rather to following this guide blindly, to understand it’s limitations and thus make your own choices based on experimentations.
What You’ll Learn
- Sparse vs dense embeddings: when and why to use each
- Hybrid architecture: SPLADE + dense + SQL
- Reciprocal Rank Fusion (RRF)
- Cross-encoder re-ranking for production precision
- Efficiency tips: tuning, storage, cost, latency
You can try everything using the same GitHub repo from Part 1:
git clone https://github.com/boutaga/pgvector_RAG_search_lab
cd pgvector_RAG_search_lab
Explore hybrid implementations in lab/search/:
hybrid_rrf.py: dense + sparse search + RRFhybrid_rerank.py: hybrid + cross-encoder rerank- Streamlit UI:
streamlit run streamlit_demo.py
Dense vs Sparse Embeddings
Dense embeddings (e.g., text-embedding-3-large) represent semantic meaning well. But for a corpus like 25K Wikipedia articles, the 3072-dim model is likely overkill. We implement it here only for testing purpose.
✅ You can use text-embedding-3-small (1536 dim) instead—it’s cheaper, faster, and nearly as accurate for homogeneous datasets. You can also check this leaderboard to verify the gains of using text-embedding-3-large or small embedding model from OpenAI : MTEB Leaderboard – a Hugging Face Space by mteb
Sparse embeddings, like those from SPLADE, model exact keyword importance via high-dimensional sparse vectors (30K+ dims). They bridge the gap between semantic and lexical search.
SPLADE vs BM25
SPLADE outperforms BM25 across benchmarks like MS MARCO and TREC for semantic-heavy queries. But BM25 is still useful when:
- Exact match is critical (codes, legal texts)
- Simplicity and explainability matter
- You need CPU-only solutions
If you are looking for the best technology out there SPLADE might be what you are looking for but FTS search algorithm is always overlooked and even today could improve alone a lot of legacy application with minimal efforts.
PostgreSQL Hybrid Search Schema
wikipedia=# \d articles
Table "public.articles"
Column | Type | Collation | Nullable | Default
------------------------+------------------+-----------+----------+---------
id | integer | | not null |
url | text | | |
title | text | | |
content | text | | |
title_vector | vector(1536) | | |
content_vector | vector(1536) | | |
vector_id | integer | | |
content_tsv | tsvector | | |
title_content_tsvector | tsvector | | |
content_sparse | sparsevec(30522) | | |
title_vector_3072 | vector(3072) | | |
content_vector_3072 | vector(3072) | | |
Indexes:
"articles_pkey" PRIMARY KEY, btree (id)
"articles_content_3072_diskann" diskann (content_vector_3072)
"articles_sparse_hnsw" hnsw (content_sparse sparsevec_cosine_ops) WITH (m='16', ef_construction='64')
"articles_title_vector_3072_diskann" diskann (title_vector_3072) WITH (storage_layout=memory_optimized, num_neighbors='50', search_list_size='100', max_alpha='1.2')
"idx_articles_content_tsv" gin (content_tsv)
"idx_articles_title_content_tsvector" gin (title_content_tsvector)
Triggers:
tsvectorupdate BEFORE INSERT OR UPDATE ON articles FOR EACH ROW EXECUTE FUNCTION articles_tsvector_trigger()
tsvupdate BEFORE INSERT OR UPDATE ON articles FOR EACH ROW EXECUTE FUNCTION articles_tsvector_trigger()
This the table structure I implemented to be able to test, Full-text search against splade with or without dense similarity search, you can also try with different indexes and see the results.
One interesting thing to note here is that you can create dense and sparse embeddings for content but for the title field it might be unnecessary since there is a high likelihood that the title is related to the content. That said, the wikipedia database has some content where you might end up nowhere either solution and only the proper chunking strategy or FTS will help you for specific terms. That edge case is for example the year articles, like ‘2007’, where the title name is the year and the content is just dates and what happened that day. So there is no relation between the year it self, the dates and the events because no where we mention year and date together and embeddings on title and content are separated. So in this case the best scenario would be to perform a normal WHERE clause search on the year you are looking for and then look into the content for similarity search for example.
Rank Fusion with RRF
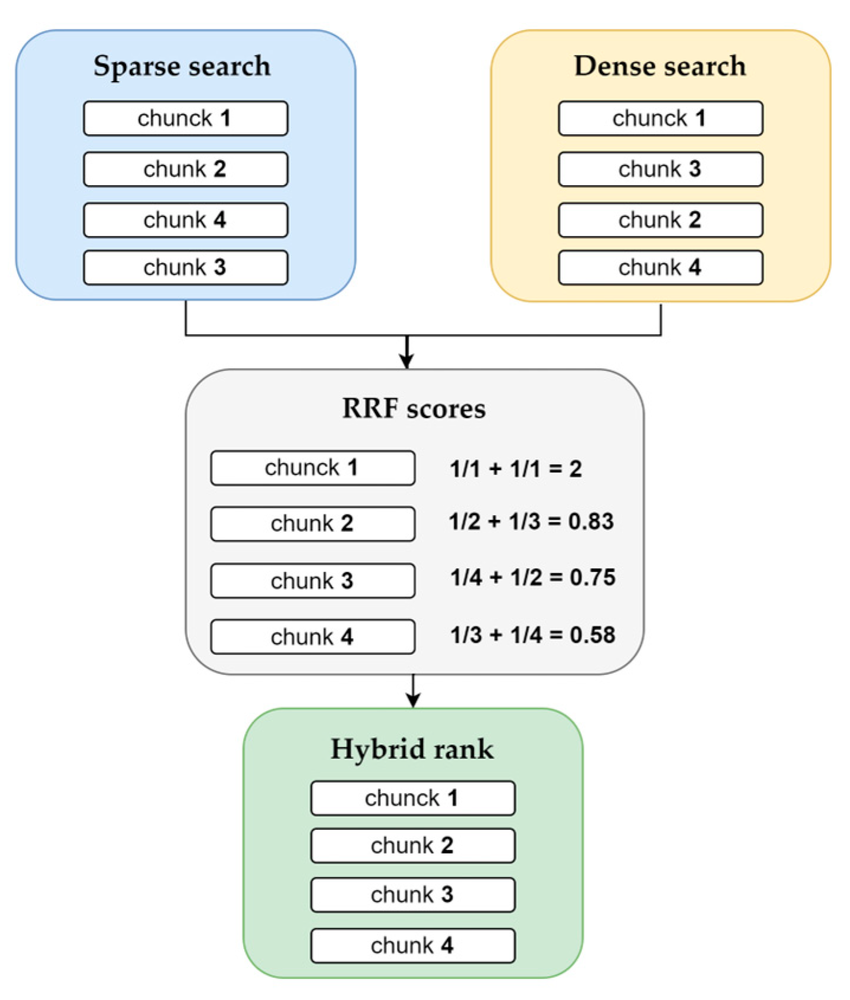
source : www.researchgate.net
We use Reciprocal Rank Fusion (RRF) to combine dense and sparse results without normalizing scores because it ranks by position not raw value.
def reciprocal_rank_fusion(rankings, k=60):
scores = {} # doc_id -> cumulative RRF score across lists
for ranking in rankings: # each 'ranking' is a list of doc_ids in order
for rank, doc_id in enumerate(ranking, 1): # ranks start at 1
scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + rank)
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
Key Insight: RRF is more robust but weighted allows fine-tuning
RRF = robust default. No calibration needed. This is a great method when score scales are incomparable or volatile across queries, or when you’re fusing many signals.
✅ Very low tuning burden (pick k≈50–100).
Hybrid Search with RRF
class RankingService:
"""
Service for ranking and merging search results.
Provides multiple ranking strategies:
- Reciprocal Rank Fusion (RRF)
- Weighted linear combination
- Score normalization
- Custom ranking functions
"""
def __init__(self, default_k: int = 60):
"""
Initialize ranking service.
Args:
default_k: Default k parameter for RRF (typically 60)
"""
self.default_k = default_k
def reciprocal_rank_fusion(
self,
result_lists: List[List[Any]],
k: Optional[int] = None,
id_func: Optional[Callable] = None,
score_func: Optional[Callable] = None
) -> List[RankedResult]:
"""
Merge multiple result lists using Reciprocal Rank Fusion.
RRF score = sum(1 / (k + rank_i)) for each list i
Args:
result_lists: List of result lists to merge
k: RRF parameter (default: 60)
id_func: Function to extract ID from result
score_func: Function to extract score from result
Returns:
Merged and ranked results
"""
k = k or self.default_k
id_func = id_func or (lambda x: x.id if hasattr(x, 'id') else x.get('id'))
score_func = score_func or (lambda x: x.score if hasattr(x, 'score') else x.get('score', 0))
# Calculate RRF scores
rrf_scores = defaultdict(float)
result_map = {}
source_map = defaultdict(list)
for list_idx, results in enumerate(result_lists):
for rank, result in enumerate(results, 1):
result_id = id_func(result)
rrf_scores[result_id] += 1.0 / (k + rank)
result_map[result_id] = result
source_map[result_id].append(f"list_{list_idx}")
# Sort by RRF score
sorted_ids = sorted(rrf_scores.keys(), key=lambda x: rrf_scores[x], reverse=True)
# Create ranked results
ranked_results = []
for rank, result_id in enumerate(sorted_ids, 1):
result = result_map[result_id]
# Extract content based on result type
if hasattr(result, 'content'):
content = result.content
elif isinstance(result, dict) and 'content' in result:
content = result['content']
else:
content = str(result)
# Extract metadata
if hasattr(result, 'metadata'):
metadata = result.metadata
elif isinstance(result, dict):
metadata = {k: v for k, v in result.items() if k not in ['id', 'content', 'score']}
else:
metadata = {}
ranked_result = RankedResult(
id=result_id,
content=content,
score=rrf_scores[result_id],
rank=rank,
metadata=metadata,
sources=source_map[result_id]
)
ranked_results.append(ranked_result)
return ranked_results
Added to the RRF method you can add some weight on each side to favor one type of embedding in the ranking like so :
if weight_combinations is None:
weight_combinations = [
(1.0, 0.0), # Dense only
(0.7, 0.3), # Dense heavy
(0.5, 0.5), # Balanced
(0.3, 0.7), # Sparse heavy
(0.0, 1.0) # Sparse only
]
When to Use Hybrid + Re-ranking
✅ Use it when:
- Queries mix keywords and concepts
- Domain has specialized or rare terms
- Precision matters (compliance, recommendations)
- Dataset is diverse or multi-modal
❌ Stick with pure dense when:
- Queries are exploratory
- Low latency is essential
- You’re just prototyping
Final Takeaways
- Hybrid search improves accuracy 8–15% over pure methods.
- PostgreSQL with
pgvectorhandles it natively—no need for external vector DBs. - RRF is simple, effective, and production-safe.
- Cross-encoder re-ranking is optional but powerful.
- Start small: tune
sparse_boost, use 1536 dims, monitor recall/failure rates.
In Part 3, we will explore adaptive RAG—dynamic query routing, confidence-based fallbacks, and agentic workflows. Hybrid search sets the foundation for those advanced RAG techniques that can help you reach your goals of integrating AI/LLM capabilities in your organization.
Try It Yourself
🔗 GitHub: pgvector_RAG_search_lab
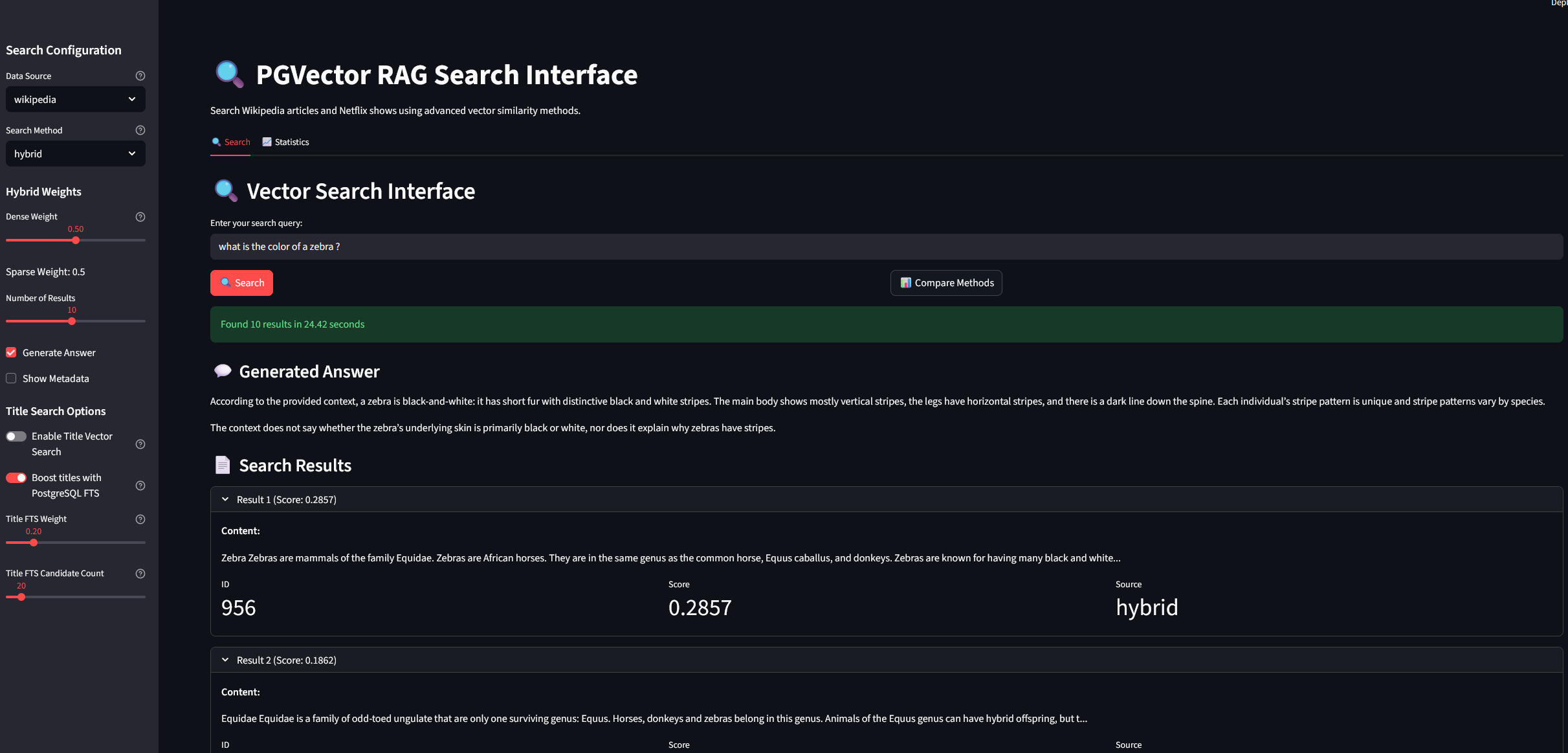
Use the included Streamlit app to compare (just be sure to embbed your query with the same model and number of dimensions than your content) :
- 🔍 Semantic-only
- 🔍 Hybrid (RRF)
- 🔍 Hybrid + re-ranking
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2025/03/OBA_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)