Introduction
In earlier parts, we moved from Naive RAG (vector search) to Hybrid RAG (dense + sparse) to Adaptive RAG (query classification and dynamic weighting). Each step improved what we retrieve. Agentic RAG goes further: the LLM decides if and when to retrieve at all and can take multiple steps (retrieve → inspect → refine → retrieve) before answering. Retrieval stops being a fixed stage and becomes a tool the model invokes when and how it needs to. This blog post will explain the fundamental principles of agentic RAG from a DBA perspective on which you can build on top of all your business logic and governance rules.
| RAG Type | Decision Logic | Flexibility | Typical Latency | Best For |
|---|---|---|---|---|
| Naive | None | Fixed | ~0.5 s | Simple FAQ |
| Hybrid | Static weights | Moderate | ~0.6 s | Mixed queries |
| Adaptive | Query classifier | Dynamic | ~0.7 s | Varied, predictable query types |
| Agentic | LLM agent (tool use) | Fully dynamic | ~2.0–2.5 s | Complex, exploratory, multi-hop |
When One Retrieval Isn’t Enough
Example: “Compare PostgreSQL and MySQL indexing approaches.”
Traditional (single-pass) RAG
- Retrieves mixed docs about both systems
- LLM synthesizes from noisy context
- Often misses nuanced differences or secondary linked subjects.
Agentic RAG
- Agent searches “PostgreSQL indexing mechanisms”
- Reads snippets; detects a gap for MySQL
- Searches “MySQL indexing mechanisms”
- Synthesizes a side-by-side comparison from focused contexts
This loop generalizes: the agent decomposes questions, detects missing context, and invokes tools until it has enough evidence to answer confidently.
Generalization is an ability for an agent to take on new tasks or variations of existing ones by reusing and combining what it already knows rather than memorizing patterns. This is very usefull to handle variations in inputs and allow an agent to adapt faster with fewer codified examples but also comes with new limitations. There are different ways to generalize and you need to measure this functionality to detect when it fails. So far we covered monitoring at the ranking level of retrieval but this part I am not going to extend on is about reliable solving new tasks or shift, one way to measure it would be implement failure detection wired to the agent logs.
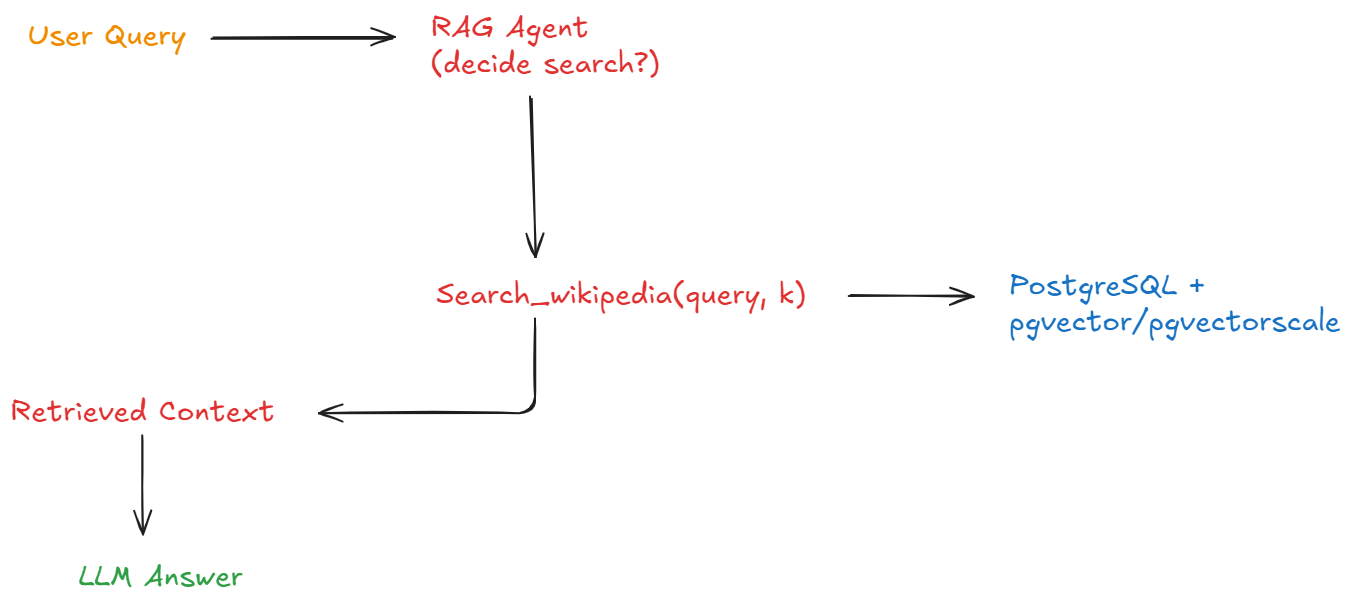
Architecture Overview
Agentic RAG inserts a decision loop between query and retrieval; the database is explicitly a tool.
About This Implementation
The code examples in this post are based on the complete, production-ready implementation
available in the pgvector_RAG_search_lab repository.
What’s included:
- ✅ Agentic search engine
- ✅ Modern OpenAI tools API
- ✅ Interactive demo and CLI
- ✅ FastAPI integration
- ✅ n8n workflow template
You don’t need to build from scratch — the implementation is ready to use. The post explains
the concepts and design decisions behind the working code.
Picking an orchestration style
| Approach | Best For | Complexity | Control |
|---|---|---|---|
| LangGraph | Production agent graphs & branches | Medium | Medium |
| n8n | Low-code demos / single-decision flows | Low | Low |
| Custom Python (ours) | Full transparency & tight DB integration | Medium | High |
We’ll keep the loop in custom Python (testable, observable), while remaining compatible with LangGraph or n8n if you want to wrap it later.
Implementing the Agent Loop (Python)
Below are compact, production-minded snippets using the new client style and gpt-5 / gpt-5-mini. We use gpt-5-mini for the decision step (cheap/fast) and gpt-5 for the final synthesis (quality). You can also run everything on gpt-5-mini if cost/latency is critical.
1) Expose the retrieval tool
# lab/search/agentic_search.py
from typing import List
from dataclasses import dataclass
@dataclass
class SearchResult:
content: str
metadata: dict
class VectorSearchService:
def __init__(self, pg_conn):
self.pg = pg_conn # psycopg / asyncpg / SQLAlchemy
def search(self, query: str, top_k: int = 5) -> List[SearchResult]:
# Implement hybrid/dense search as in prior posts; this is the dense-only core.
# SELECT title, text FROM wiki ORDER BY embedding <-> embed($1) LIMIT $2;
...
def format_snippets(results: List[SearchResult]) -> str:
lines = []
for i, r in enumerate(results, 1):
title = r.metadata.get("title", "Untitled")
snippet = (r.content or "").replace("\n", " ")[:220]
lines.append(f"[{i}] {title}: {snippet}...")
return "\n".join(lines)
def search_wikipedia(vector_service: VectorSearchService, query: str, top_k: int = 5) -> str:
results = vector_service.search(query, top_k=top_k)
return format_snippets(results)
2) Register tool schema for the LLM
search_tool = {
"type": "function",
"function": {
"name": "search_wikipedia",
"description": "Retrieve relevant Wikipedia snippets from Postgres+pgvector.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"},
"top_k": {"type": "integer", "default": 5}
},
"required": ["query"]
}
}
}
3) Prompts (concise, outcome-oriented)
SYSTEM_PROMPT = """
You are an expert assistant with access to a Wikipedia database via the tool `search_wikipedia`.
Decide if retrieval is needed before answering. If you are unsure, retrieve first.
If context is insufficient after the first retrieval, you may request one additional retrieval.
Base answers strictly on provided snippets; otherwise reply "Unknown".
Conclude with a one-line decision note: `Decision: used search` or `Decision: skipped search`.
"""
4) The agent loop with gpt-5-mini (decision) + gpt-5 (final)
import json, time
from openai import OpenAI
client = OpenAI()
def agentic_answer(pg_conn, user_question: str, max_retries: int = 1):
vs = VectorSearchService(pg_conn)
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_question},
]
# Phase 1: Decision / planning (cheap & fast)
start = time.time()
decision = client.chat.completions.create(
model="gpt-5-mini",
messages=messages,
tools=[search_tool],
tool_choice="auto", # let the model decide
temperature=0.2,
)
msg = decision.choices[0].message
tool_used = False
loops = 0
# Handle tool calls (allow at most 1 retry cycle)
while msg.tool_calls and loops <= max_retries:
tool_used = True
call = msg.tool_calls[0]
args = json.loads(call.function.arguments or "{}")
query = args.get("query") or user_question
top_k = int(args.get("top_k") or 5)
snippets = search_wikipedia(vs, query=query, top_k=top_k)
if not snippets.strip():
# No results safeguard
messages += [msg, {"role": "tool", "name": "search_wikipedia", "content": "NO_RESULTS"}]
break
messages += [
msg,
{"role": "tool", "name": "search_wikipedia", "content": snippets}
]
# Optionally allow one more decision round on mini
decision = client.chat.completions.create(
model="gpt-5-mini",
messages=messages,
tools=[search_tool],
tool_choice="auto",
temperature=0.2,
)
msg = decision.choices[0].message
loops += 1
# Phase 2: Final synthesis (high quality)
final = client.chat.completions.create(
model="gpt-5",
messages=messages + ([msg] if not msg.tool_calls else []),
tool_choice="none",
temperature=0.3,
)
answer = final.choices[0].message.content or "Unknown"
total_ms = int((time.time() - start) * 1000)
return {
"answer": answer,
"tool_used": tool_used,
"loops": loops,
"latency_ms": total_ms,
}
We use gpt-5-mini for the decision step (cheap/fast) and gpt-5 for the final synthesis (quality).
The two-phase strategy (gpt-5-mini for decisions, gpt-5 for synthesis)
is an optional optimization for high-volume production use. The repository implementation uses a
single configurable model (default: gpt-5-mini) which works well for most use cases. Implement the
two-phase approach only if you need to optimize the cost/quality balance.
Decision logic
| LLM Output | Action | Next Step |
|---|---|---|
| Direct answer | Return | Done |
| Tool call | Execute search | Feed snippets back; allow one re-decision |
| Tool call + no results | Log low confidence | Stop (avoid loops) → “Unknown” |
Guards
- Max loop (
max_retries) to prevent infinite cycles - Empty-results check
- Low temperature for consistent decisions
- Optional rate limiting (e.g., sleep/backoff) if your OpenAI or DB tier needs it
Evaluating Agentic Decisions
Agentic RAG adds a new layer to measure: decision quality. Keep the retrieval metrics (precision@k, nDCG), but add decision metrics and overhead.
1) Decision Accuracy (4 outcomes)
- TP (True Positive): Agent retrieved when external info was needed ✓
- FP (false Positive): Agent retrieved unnecessarily (latency/cost waste)
- FN (False Negative): Agent skipped retrieval but should have (hallucination risk)
- TN (True Negative): Agent skipped retrieval appropriately ✓
- N : total questions evaluated
Accuracy = (TP + TN) / N
Interpretation:
- How often did the agent make the right call about retrieval?
- “Right call” means either:
- it retrieved when it should (TP), or
- it skipped when it could safely skip (TN).
Example:
- TP = 40
- TN = 50
- FP = 5
- FN = 5
- N = 100
Accuracy = (40 + 50) / 100 = 90%
That means: in 90% of cases, the agent made the correct decision about using retrieval.
Note: This doesn’t judge how good the final answer is — that’s a separate metric. This only measures the decision to retrieve or not retrieve.
2) Tool Usage Rate
% of queries that triggered retrieval.
Too low → overconfident model; too high → cautious and costly. Track per domain/query type.
3) Latency/Cost Impact
| Scenario | LLM Calls | DB Queries | Avg Latency |
|---|---|---|---|
| No retrieval | 1 | 0 | ~0.5 s |
| Single retrieval | 2 | 1 | ~2.1 s |
| Double retrieval | 3 | 2 | ~3.8 s |
Report both p50/p95 to capture long-tail tool loops.
4) Answer Quality (Agentic vs. Adaptive)
Run the same query set through Adaptive and Agentic:
- Compare precision@k/nDCG of retrieved sets
- Human-rate final answers for factuality and completeness
- Track “Unknown” rate (good: avoids hallucination; too high: under-retrieval)
Tip: log a one-liner in every response:decision=used_search|skipped_search loops=0|1 latency_ms=...
When Agentic RAG May Not Be Worth It
Prefer Adaptive if:
- p95 latency must be <1s (agentic adds ~1-2s when searching)
- Requests are predictable and schema-bound
- Compliance needs strong deterministic behavior
- Token cost is primary constraint
Choose Agentic when:
- Queries are exploratory / multi-hop
- Multiple tools or sources are available
- Context quality > raw speed
- You’re building research assistants, not simple FAQ bots
Repository Integration (pgvector_RAG_search_lab)
Proposed tree
lab/
├── search/
| |__ ...other search scritps
│ ├── agentic_search.py # Main agentic engine
│ └── examples/
│ └── agentic_demo.py # Interactive demo
├── core/
│ └── generation.py # Includes generate_with_tools() for function calling
├── api/
│ └── fastapi_server.py # REST endpoint: POST /search with method="agentic"
├── workflows/
│ └── agentic_rag_workflow.json # n8n visual workflow
└── evaluation/
└── metrics.py # nDCG and ranking metrics (not agentic-specific)
FastAPI endpoint (sketch)
# lab/search/api_agentic.py
from fastapi import APIRouter
from .agentic_search import agentic_answer
router = APIRouter()
@router.post("/agent_search")
def agent_search(payload: dict):
q = payload.get("query", "")
result = agentic_answer(pg_conn=..., user_question=q)
return result
n8n (optional)
- Manual trigger → HTTP Request
/agent_search→ Markdown render - Show 🔄 if
tool_used: trueand add latency badge
LangGraph (optional)
- Map our tool into a graph node; Agent node → Tool node → Agent node
- Useful if you later add web search / SQL tools in parallel branches
Prompt Tips (small changes, big impact)
| Goal | Prompt Additions |
|---|---|
| Fewer false positives | “Only search when facts are needed; avoid unnecessary retrieval.” |
| Fewer false negatives | “Never guess facts; reply ‘Unknown’ if not in snippets.” |
| Lower latency | “Limit to at most one additional retrieval if context is missing.” |
| Better observability | “End with: Decision: used search or Decision: skipped search.” |
Quickstart
git clone https://github.com/boutaga/pgvector_RAG_search_lab
cd pgvector_RAG_search_lab
# Export your API key
export OPENAI_API_KEY=...
# Interactive demo (recommended first try)
python lab/search/examples/agentic_demo.py
# Command-line single query
python lab/search/agentic_search.py \
--source wikipedia \
--query "Compare PostgreSQL and MySQL indexing" \
--show-decision \
--show-sources
# Interactive mode
python lab/search/agentic_search.py --source wikipedia --interactive
# Start API server
python lab/api/fastapi_server.py
# Call API endpoint
curl -X POST http://localhost:8000/search \
-H "Content-Type: application/json" \
-d '{
"query": "How does PostgreSQL MVCC work?",
"method": "agentic",
"source": "wikipedia",
"top_k": 5,
"generate_answer": true
}'
Appendix A — Minimal “all-mini” variant (cheapest path)
# Use gpt-5-mini for both phases
resp = client.chat.completions.create(
model="gpt-5-mini",
messages=messages,
tools=[search_tool],
tool_choice="auto",
temperature=0.2,
)
# ... identical loop, then final:
final = client.chat.completions.create(
model="gpt-5-mini",
messages=messages + ([msg] if not msg.tool_calls else []),
tool_choice="none",
temperature=0.3,
)
Appendix B — Simple metrics logger
# lab/search/metrics.py
from dataclasses import dataclass
@dataclass
class DecisionLog:
query: str
tool_used: bool
loops: int
latency_ms: int
label_retrieval_required: bool | None = None # optional gold label
hallucinated: bool | None = None # set via eval
def summarize(logs: list[DecisionLog]):
n = len(logs)
usage = sum(1 for x in logs if x.tool_used) / n
p95 = sorted(x.latency_ms for x in logs)[int(0.95 * n) - 1]
# If labels present, compute TP/FP/FN/TN
labeled = [x for x in logs if x.label_retrieval_required is not None]
if labeled:
tp = sum(1 for x in labeled if x.tool_used and x.label_retrieval_required)
tn = sum(1 for x in labeled if (not x.tool_used) and (not x.label_retrieval_required))
acc = (tp + tn) / len(labeled)
else:
acc = None
return {"tool_usage_rate": usage, "p95_latency_ms": p95, "decision_accuracy": acc}
This is a simplified example for illustration. The repository currently tracks decision
metadata within the response object (decision, tool_used, search_count, cost). You can
implement this DecisionLog class separately if you need persistent decision analytics.
Conclusion
Agentic RAG makes retrieval intentional. By letting the model decide if and when to search—and by limiting the loop to one safe retry—you gain better answers on complex queries with measured, predictable overhead.
Takeaways
- Expect latency to be several seconds when the tool is used; near-naive latency when skipped
- Measure decision accuracy and tool usage rate alongside precision/nDCG
- Start with one tool (wiki search) and one retry; expand only if metrics justify it
- Use smaller models for decisions and bigger ones for synthesis to balance quality/cost
In this post we focused only on retrieval quality — teaching the agent when to call the vector store and when to skip it, and giving it a controlled retrieval loop, that’s the foundation. The next step is to extend the loop with governance and compliance checks (who is asking, what data can they see, should this query even be answered), and only then layer domain-specific business logic on top. That’s how an agentic workflow evolves from “smart retrieval” into something you can actually trust in production.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2025/03/OBA_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)