Errors in tasks – abort or ignore?
Per default, if a task in a playbook fails, then the execution of the playbook is stopped for that host.
- name: PLAY1
hosts: localhost
gather_facts: no
tasks:
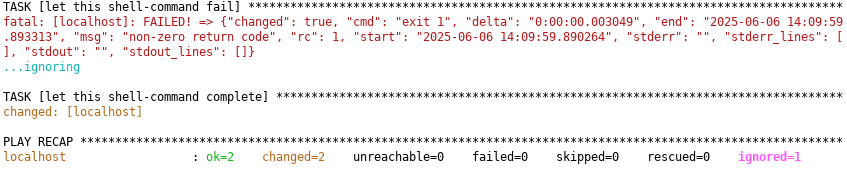
- name: let this shell-command fail
ansible.builtin.shell: exit 1
- name: let this shell-command complete
ansible.builtin.shell: exit 0

As you can see, the 2nd task is not executed. If you want to continue in such a case, the ignore_errors parameter is your friend
- name: let this shell-command fail
ansible.builtin.shell: exit 1
ignore_errors: true
Custom error conditions
Per default, Ansible evaluates the exit-code of the module, in case of the shell-module, the exit-code of the last command.
But for some commands, that is not adequate. Example: The Oracle commandline tool sqlplus to submit sql-commands will have an exit-code of 0 if it can connect to the database-instance. It is not related to the result of your SQL-commands. Error-messages in Oracle are prefixed by ORA-.
So, if you want to check for application errors, you have to implement it yourself. For that, you can use the failed_when option.
- name: let this shell-command fail
ansible.builtin.shell: |
. ~/.profile
echo "select count(*) from all_users;" | sqlplus / as sysdba
register: number_of_users
failed_when: "'ORA-' in number_of_users.stdout"
Caution: In this case the exit-code of the shell is no longer evaluated. To also get the exit-code of the sqlplus call (e.g., sqlplus can not connect to the database, or sqlplus binary not found), you have to add this (default) condition:
failed_when: "number_of_users.rc != 0 or 'ORA-' in number_of_users.stdout"
But caution! Not all modules will have an rc field.
Tuning: Perform several checks at once
Conceptually, Ansible is not the fastest tool. For each task, it will usually login with ssh to the remote server. If you have to run several checks in the shell, then, instead of running each in a separate task, you can run all these check-commands in one shell-task, and evaluate the result afterwards.
- name: run many check commands
ansible.builtin.shell: |
mount | grep ' on /u00 ' #check if /u00 is mounted
rpm -q ksh 2>&1 #check if ksh is installed
exit 0 # do not fail if rpm exit != 0; we will do our own errorhandling
register: checks
- name: fail if no /u00 is mounted
fail:
msg: "/u00 is not mounted"
when: "' on /u00 ' not in checks.stdout"
- name: No ksh found, try to install it
yum:
name: ksh
state: present
when: "'package ksh is not installed' in checks.stdout"
If you only want to throw an error, then you can do it directly in the shell-task:
when: "' on /u00 ' not in checks.stdout" or 'package ksh is not installed' in checks.stdout
But if you parse the output afterwards, you can run tasks to fix the error.
Sometimes it is difficult to parse the output if some commands return the same output, e.g. “OK”.
If your check-commands always return exactly 1 line, then you can directly parse the output of the command. The output of the 3rd command is in checks.stdout_lines[2].
In the above example that will not work because grep will return the exit-code 0 (not found) or 1 (found) plus the found line. So, expand it as: mount | grep ' on /u00 ' || echo error
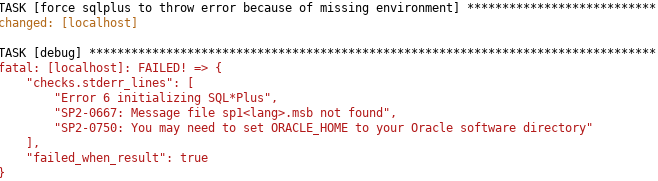
Print errormessages more readable
Do not fail the task itself, it is very usually unreadable because all information is printed on one line.

Instead, use ignore_errors: true and failed_when: false in the task. Do the errorhandling in a separate task with a customized errormessage. To print the multiline list of stdout_lines, use debug: otherwise you can directy use ansible.builtin.fail: with a customized message:
- name: force sqlplus to throw error because of missing environment
ansible.builtin.shell: |
/u00/app/oracle/product/19.7.0/bin/sqlplus -L / as sysdba @myscript.sql 2>&1
register: checks
ignore_errors: true
failed_when: false
- name: Check for errors of task before
debug: var=checks.stdout_lines
failed_when: checks.rc != 0 or 'ORA-' in checks.stdout
when: checks.rc != 0 or 'ORA-' in checks.stdout
Re-run failed hosts
As an example for this scenario: A customer of mine will do an offline backup of the development databases. And I have to run an Ansible playbook against all databases. If the playbook for this host is run at the backup time, it will fail because the database is down. But after some minutes the database will be restarted.
What we can do now?
Wait until the database is up again. That is possible, see the example of ansible.builtin.wait_for in my blog post Parallel execution of Ansible roles. But for this scenario it is a waste of time. The database can be stopped (not for backup) and will not be restarted within the next few minutes.
Try later after a while. My playbook for all hosts (parallel forks=5) takes about 1 hour. The idea now is to remember the host with the stopped database and to continue with the next host. After the play finished for all hosts, restart the play for the remembered hosts.
- The 1st play running against all database hosts:
- gets the status of the databases on the host
- assigns the database instances to a
is_runningand anot_openlist - Include the role to run against the running databases
- Dynamically add the host to the group
re_run_if_not_openif there arenot_opendatabases
- The next play only runs for the
re_run_if_not_opengroup - Include the role to run against the (hopefully now running) databases
- If the database then is still down, we assume it is stopped permanently.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2025/05/martin_bracher_2048x1536.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/NAC_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/HER_web-min-scaled.jpg)