Context
In the era of digital transformation, attack surfaces are constantly evolving and cyberattack techniques are becoming increasingly sophisticated. Maintaining the confidentiality, integrity, and availability of data is therefore a critical challenge for organizations, both from an operational and a regulatory standpoint (GDPR, ISO 27001, NIST). Therefore, data anonymization is crucial today.
Contrary to a widely held belief, the risk is not limited to the production environment. Development, testing, and pre-production environments are prime targets for attackers, as they often benefit from weaker security controls. The use of production data that is neither anonymized nor pseudonymized directly exposes organizations to data breaches, regulatory non-compliance, and legal sanctions.
Why and How to Anonymize Data
Development teams require realistic datasets in order to:
- Test application performance
- Validate complex business processes
- Reproduce error scenarios
- Train Business Intelligence or Machine Learning algorithms
However, the use of real data requires the implementation of anonymization or pseudonymization mechanisms ensuring:
- Preservation of functional and referential consistency
- Prevention of data subject re-identification
Among the possible anonymization techniques, the main ones include:
- Dynamic Data Masking, applied on-the-fly at access time but which does not anonymize data physically
- Tokenization, which replaces a value with a surrogate identifier
- Cryptographic hashing, with or without salting
Direct data copy from Production to Development
In this scenario, a full backup of the production database is restored into a development environment. Anonymization is then applied using manually developed SQL scripts or ETL processes.
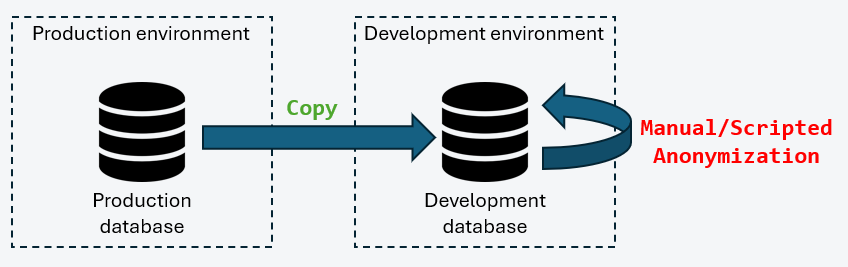
This approach presents several critical weaknesses:
- Temporary exposure of personal data in clear text
- Lack of formal traceability of anonymization processes
- Risk of human error in scripts
- Non-compliance with GDPR requirements
This model should therefore be avoided in regulated environments.
Data copy via a Staging Database in Production
This model introduces an intermediate staging database located within a security perimeter equivalent to that of production. Anonymization is performed within this secure zone before replication to non-production environments.
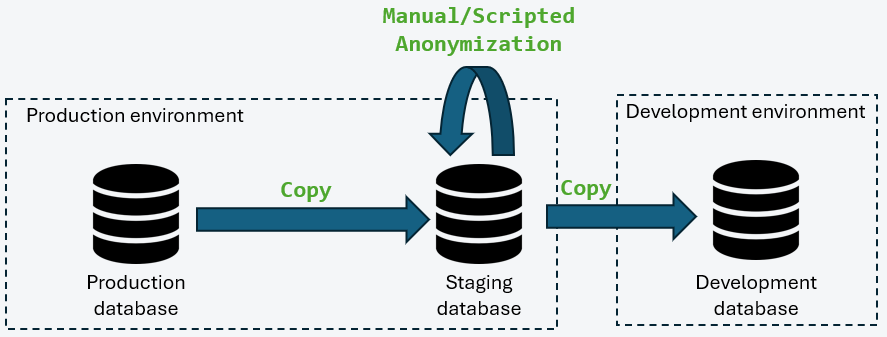
This approach makes it possible to:
- Ensure that no sensitive data in clear text leaves the secure perimeter
- Centralize anonymization rules
- Improve overall data governance
However, several challenges remain:
- Versioning and auditability of transformation rules
- Governance of responsibilities between teams (DBAs, security, business units)
- Maintaining inter-table referential integrity
- Performance management during large-scale anonymization
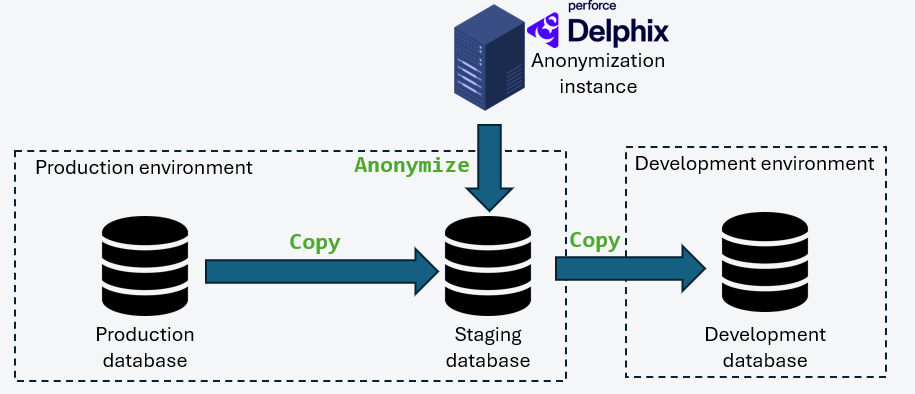
Integration of Delphix Continuous Compliance
In this architecture, Delphix is integrated as the central engine for data virtualization and anonymization. The Continuous Compliance module enables process industrialization through:
- An automated data profiler identifying sensitive fields
- Deterministic or non-deterministic anonymization algorithms
- Massively parallelized execution
- Orchestration via REST APIs integrable into CI/CD pipelines
- Full traceability of processing for audit purposes
This approach enables the rapid provisioning of compliant, reproducible, and secure databases for all technical teams.
Conclusion
Database anonymization should no longer be viewed as a one-time constraint but as a structuring process within the data lifecycle. It is based on three fundamental pillars:
- Governance
- Pipeline industrialization
- Regulatory compliance
An in-house implementation is possible, but it requires a high level of organizational maturity, strong skills in anonymization algorithms, data engineering, and security, as well as a strict audit framework. Solutions such as Delphix provide an industrialized response to these challenges while reducing both operational and regulatory risks.
To take this further, Microsoft’s article explaining the integration of Delphix into Azure pipelines analyzes the same issues discussed above, but this time in the context of the cloud : Use Delphix for Data Masking in Azure Data Factory and Azure Synapse Analytics
What’s next ?
This use case is just one example of how Delphix can be leveraged to optimize data management and compliance in complex environments. In upcoming articles, we will explore other recurring challenges, highlighting both possible in-house approaches and industrialized solutions with Delphix, to provide a broader technical perspective on data virtualization, security, and performance optimization.
What about you ?
How confident are you about the management of your confidential data?
If you have any doubts, please don’t hesitate to reach out to me to discuss them !
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/05/martin_bracher_2048x1536.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)